Way back in 2016, I backed the Pocket C.H.I.P on Kickstarter opting to get 2 CHIP’s and one PocketChip. The C.H.I.P (or CHIP) was a single single-board computer costing $9 launched by Next Thing Co. It used open-source hardware running open-source software and was advertised as world’s first $9 computer as a direct competitor to the RaspberryPi . The device boasted the following configuration:
- 1 GHz R8M/R8 (ARMv7)SoC processor
- 512 MB DDR3 SDRAM
- Built-in Wi-Fi 802.11b/g/n, Bluetooth 4.0
- One USB host with type-A receptacle, one USB On-The-Go port
- Composite video and stereo audio port via mini TRRS
- Optional composite TRRS to RCA audio-video cable
- Optional VGA adapter and HDMI adapter (I got both)
- Up to 45 GPIO ports
- Supports 1-Wire and I2C protocols, PWM output
- Serial console and Ethernet via USB for quick headless operation
- Power options include 5V via USB OTG, 5V via CHN pin, and by 3.7V battery
- Onboard NAND storage, 4-8GB
The PocketChip was a handheld with a 4.3 inch 480×272 pixel resistive touchscreen, a clicky keyboard, GPIO headers on the top of the device, and GPIO soldering pads inside of the injection molded case powered by the CHIP processor. It looks clunky but is easier to connect to the device and setup using the PocketChip rather than doing it with just the CHIP.
Unfortunately the company shutdown in 2018 due to various issues. However, I was one of the lucky backers to receive the devices but once I received them I put them in a drawer and kind of forgot about them as life got busy and interesting. Over the years I did try to power on the device a couple of times but never really looked into getting it to work, so they just collected dust in my desk (literally).
Over the past weekend I decided to try getting it to work so I did some searching and with a lot of trial and error finally managed to get things to work and boot into a working OS. 🙂 The main issue was that I was expecting it to work like the RaspberryPi where the OS was installed on an SD card but in this case the OS had to be flashed on to the onboard flash chip which was a bit more complicated process than installing to a SD card. I followed the instructions at NextThingCo Pocket C.H.I.P. Flashing Guide amongst other pages to get things to work. Here I will document some of the other things I had to do to get it to work. Please note that this was on a Debian setup, things might be a bit different for other OS’s
Install the Prerequisites
First we need to install the tools required by running the following command as root:
apt-get install git android-tools-fastboot sunxi-tools u-boot-tools
Download the CHIP SDK
Download the CHIP-SDK.zip from one of the following links:
Download and extract the CHIP Tools
Download CHIP-tools.zip from one of the following sites:
Download CHIP OS Images
Download the CHIP OS image from one of the following links:
Extract flash-collection.zip
When I tried extracting the contents of the zip file I got from the first link, I got an error that the file is not a Zip file. After a lot of searching I found out that you can run the following command to extract the file instead:
jar xfv flash-collection.zip
Since that seems unnecessarily complicated. I have extracted and re-compressed the file and shared it at the second link. You can extract it using the standard zip tools.
Fix fastboot
The version of fastboot in the Debian repositories is newer than the one used in the setup scripts and if you try to flash with the version installed then fails with the following error message:
..
..
== Cached UBI located ==
Image Name: flash server
Created: Sun Aug 20 19:29:14 2023
Image Type: ARM Linux Script (uncompressed)
Data Size: 1784 Bytes = 1.74 KiB = 0.00 MiB
Load Address: 00000000
Entry Point: 00000000
Contents:
Image 0: 1776 Bytes = 1.73 KiB = 0.00 MiB
waiting for fel...OK
waiting for fastboot...fastboot: invalid option -- 'i'
.fastboot: invalid option -- 'i'
.fastboot: invalid option -- 'i'
.fastboot: invalid option -- 'i'
.fastboot: invalid option -- 'i'
.fastboot: invalid option -- 'i'
.fastboot: invalid option -- 'i'
.fastboot: invalid option -- 'i'
The easiest fix for this is to rollback to a previous version of the software that supports the -i parameter. You can try to search and download the older version from Debian’s repositories, but I found it easier to download the software from platform-tools_r26.0.0-linux.zip (as I was too tired to go search for it in the archives)
Once you download the file and extract the contents, follow these steps to rollback to the previous version of fastboot:
- Backup the existing binary for fastboot
mv /usr/lib/android-sdk/platform-tools/fastboot /usr/lib/android-sdk/platform-tools/fastboot_old
Copy the extracted file from the zip file to the correct location
mv platform-tools/fastboot /usr/lib/android-sdk/platform-tools/fastboot
Put the CHIP in FEL mode
The FEL mode allows the software to flash the CHIP with a new firmware. This can be done by putting a jumper wire between GND and FEL. It will look something like the following:

Connecting a jumper wire between GND and FEL to enter FEL Mode
Once you have entered the FEL mode, connect the CHIP to the computer using the microUSB port on the CHIP, not the fullsize USB port.
Flashing the OS to CHIP
Once you have downloaded all the files and unziped them. Follow these steps to Flash the OS to CHIP.
- Move the CHIP-tools directory to the CHIP-SDK directory
mv CHIP-tools CHIP-SDK/
Select the Image you want to install and move it into the CHIP-SDK directory. There are 8 Images to choose from, I tested with the testing-server-b543 and testing-pocketchip-b667 images as I have 2 CHIPS to play with. 🙂
The original instructions on the site ask you to run the ./setup_ubuntu1404.sh script located in the CHIP-SDK directory but it failed most commands on my system. I think that you should be able to proceed without running it but haven’t tried it.
Switch to the CHIP-tools directory
cd CHIP-SDK/CHIP-tools
Run the firmware upgrade script, replacing Path/To/Chip/Image with the location where you extracted the Image you want to install
./chip-update-firmware.sh -L ../../flash-collection/testing-server-b543/
If you have done everything correctly and nothing is broken, you will get an output similar to the following:
suramya@StarKnight:~/Media/Downloads/CHIP/CHIP-SDK/CHIP-tools$ ./chip-update-firmware.sh -L ../testing-pocketchip-b667/
== Local directory '../testing-pocketchip-b667/' selected ==
== preparing images ==
== Local/cached probe files located ==
== Staging for NAND probe ==
Image Name: detect NAND
Created: Sun Aug 20 20:24:50 2023
Image Type: ARM Linux Script (uncompressed)
Data Size: 97 Bytes = 0.09 KiB = 0.00 MiB
Load Address: 00000000
Entry Point: 00000000
Contents:
Image 0: 89 Bytes = 0.09 KiB = 0.00 MiB
waiting for fel...OK
waiting for fel......OK
NAND detected:
nand_erasesize=400000
nand_oobsize=680
nand_writesize=4000
== Cached UBI located ==
Image Name: flash server
Created: Sun Aug 20 20:24:58 2023
Image Type: ARM Linux Script (uncompressed)
Data Size: 1784 Bytes = 1.74 KiB = 0.00 MiB
Load Address: 00000000
Entry Point: 00000000
Contents:
Image 0: 1776 Bytes = 1.73 KiB = 0.00 MiB
waiting for fel...OK
waiting for fastboot...................OK
target reported max download size of 33554432 bytes
sending sparse 'UBI' 1/23 (28672 KB)...
OKAY [ 2.016s]
writing 'UBI' 1/23...
OKAY [ 2.069s]
sending sparse 'UBI' 2/23 (28672 KB)...
OKAY [ 2.007s]
writing 'UBI' 2/23...
OKAY [ 5.484s]
..
..
sending sparse 'UBI' 22/23 (28672 KB)...
OKAY [ 1.916s]
writing 'UBI' 22/23...
OKAY [ 9.079s]
sending sparse 'UBI' 23/23 (16384 KB)...
OKAY [ 1.105s]
writing 'UBI' 23/23...
OKAY [ 4.981s]
finished. total time: 300.744s
resuming boot...
OKAY [ 0.000s]
finished. total time: 0.000s
FLASH VERIFICATION COMPLETE.
# # #
#########
### ###
# {#} #
### '%######
# #
### ###
########
# # #
CHIP is ready to roll!
If you see the message that “FLASH VERIFICATION COMPLETE.” and that “CHIP is ready to roll!”, then the OS installation has completed successfully. Now you can disconnect the CHIP from the computer and remove the jumper cable.
Booting into CHIP
If you have the PocketCHIP, then you can just power up the device by pressing on the power button for a second (pressing it for 10 seconds shuts it down forcefully). If you just have the CHIP, you will need to connect it to a monitor and connect a keyboard as well. (I used the PocketCHIP to configure everything and then used it separately).
The boot up process can take a minute or two, and assuming everything went well you should see the standard boot messages on the screen. Once you get to the login prompt you can log in using the username ‘chip’ (without the quotes) and ‘chip’ (without the quotes) as the password. The root account password is also ‘chip’ (without the quotes).
Connecting to WiFi and configuring the CHIP
The first thing that you should do now is connect the device to a WiFi network so that you can SSH into it for ease of configuration. The second thing should be to change the default passwords 🙂
The easiest way to configure WiFi is to use the nmcli tool. Run the following command as root to connect to the WiFi. More details on the command are available at How to Connect Wi-Fi from Linux Terminal Using Nmcli Command
nmcli dev wifi connect <SSID of The Network to Connect With> password <password for the Wifi Network>
Once the device is connected to the WiFi, get your IP address using the following command:
ip address
Then you can SSH into the device from any system using the IP address.
CHIP is working!!!
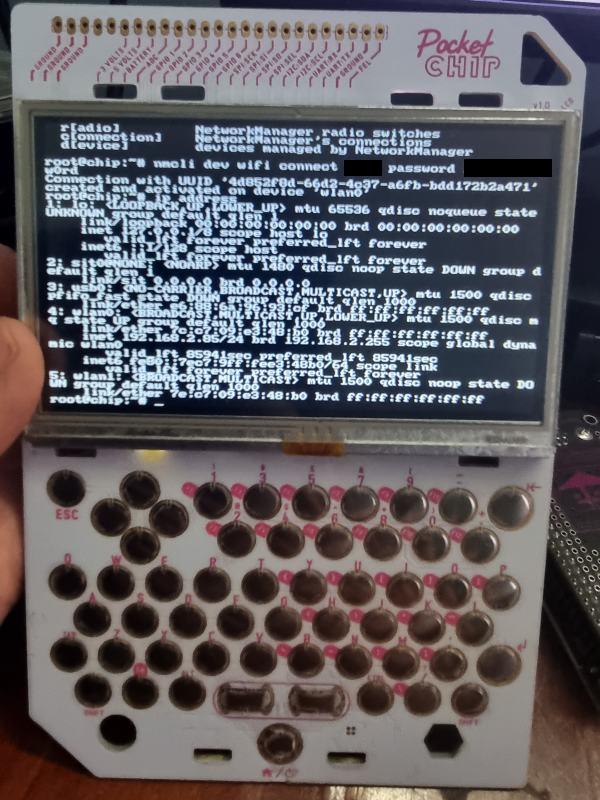
Running Debian 8 Testing
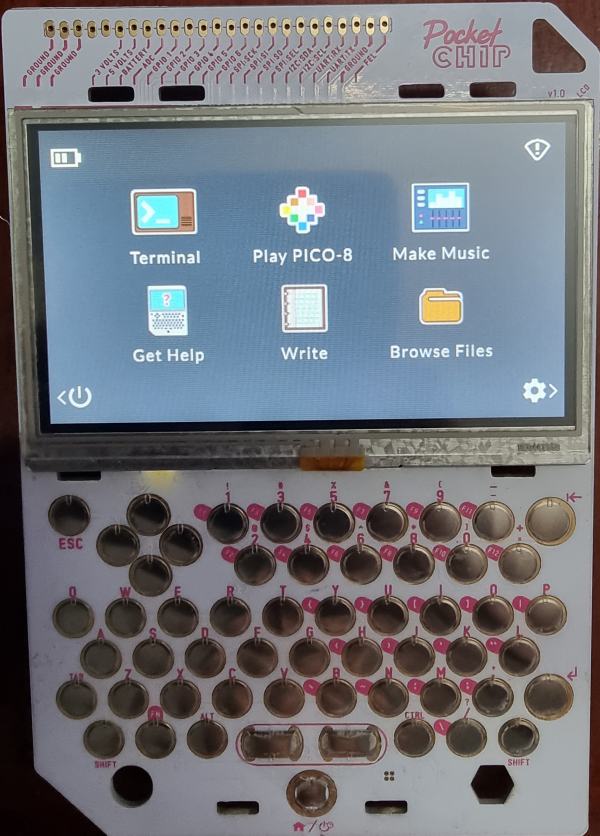
Running the PocketCHIP customized version (Debian 8)
Updating the OS to the latest version
The system is running Debian 8 by default and you should upgrade it to the latest version. Unfortunately, I keep getting errors when I try to upgrade to the latest Debian version and haven’t yet fixed the problem. Basically, I think you need to update the /etc/apt/sources.list with the correct mirror details and then upgrade. Once I get some time to revisit the setup and resolve the issue I will post the fix on the blog as a followup post to this one.
– Suramya
#CHIP #chipsters #Linux #SBC