One of the key aspects of Inclusion is Inclusive language, and its very easy to use non-inclusive/gender specific language in our everyday writings. For example, when you meet a mixed gender group of people almost everyone will say something to the effect of ‘Hey Guys’. I was guilty of the same and it took a concentrated effort on my part to change my greeting to ‘Hey Folks’ and other similar changes. Its the same case with written communication and most people default to male gender focused writing. Recently I found out that Microsoft Office‘s correction tools, which most might associate with bad grammar or improper verb usage, secretly have options that help catch non-inclusive language, including gender and sexuality bias. So I wanted to share it with everyone.
Below are instructions on how to find & enable the settings:
- Open MS Word
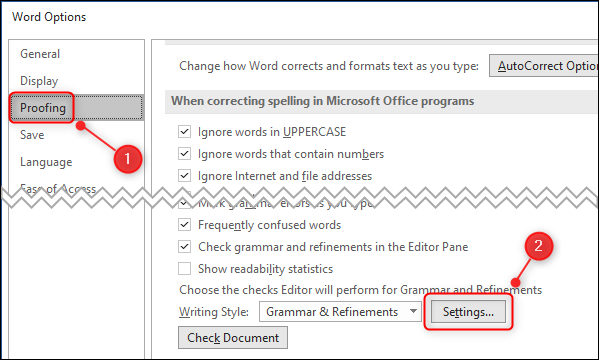
- Click on File -> Options
- Select ‘Proofing’ from the menu in the left corner and then scroll down on the right side to ‘Writing Style’ and click on the ‘Settings’ button.
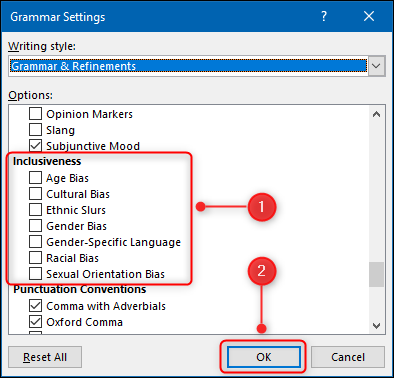
- Scroll down to the “Inclusiveness” section, select all of the checkboxes that you want Word to check for in your documents, and click the “OK” button. In some versions of Word you will need to scroll down to the ‘Inclusive Language’ section (its all the way near the bottom) and check the ‘Gender-Specific Language’ box instead.
- Click Ok
It doesn’t sound like a big deal when you refer to someone by the wrong gender but trust me its a big deal. If you don’t believe me try addressing a group of men as ‘Hello Ladies’ and then wait for the reactions. If you can’t address a group of guys as ladies then you shouldn’t refer to a group of ladies as guys either. I think it is common courtesy and requires minimal effort over the long term (Initially things will feel a bit awkward but then you get used to it).
Well this is all for now. Will write more later.
– Suramya