Writing Unit Test cases for your software is one of the most boring parts of Software Development even though having accurate tests allows us to develop code faster & with more confidence. Having a full test suite allows a developer to ensure that the changes they have made didn’t break other parts of the project that were working fine earlier. This make Unit tests an essential part of CI/CD (Continuous Integration and Continuous Delivery) pipelines. It is therefore hard to do frequent releases without rigorous unit testing. For example SQLite database engine has 640 times as much testing code as code in the engine itself:
As of version 3.33.0 (2020-08-14), the SQLite library consists of approximately 143.4 KSLOC of C code. (KSLOC means thousands of “Source Lines Of Code” or, in other words, lines of code excluding blank lines and comments.) By comparison, the project has 640 times as much test code and test scripts – 91911.0 KSLOC.
Unfortunately, since the tests are boring and don’t give immediate tangible results they are the first casualties when a team is under a time crunch for delivery. This is where Diffblue’s Cover comes into play. Diffblue was spun out of the University of Oxford following their research into how to use AI to write tests automatically. Cover uses AI to write a complete Unit Test including logic that reflects the behavior of the program as compared to the other existing tools that generate Unit Tests based on Templates and depend on the user to provide the logic for the test.
Cover has now been released as a free Community Edition for people to see what the tool can do and try it out themselves. You can download the software from here, and the full datasheet on the software is available here.
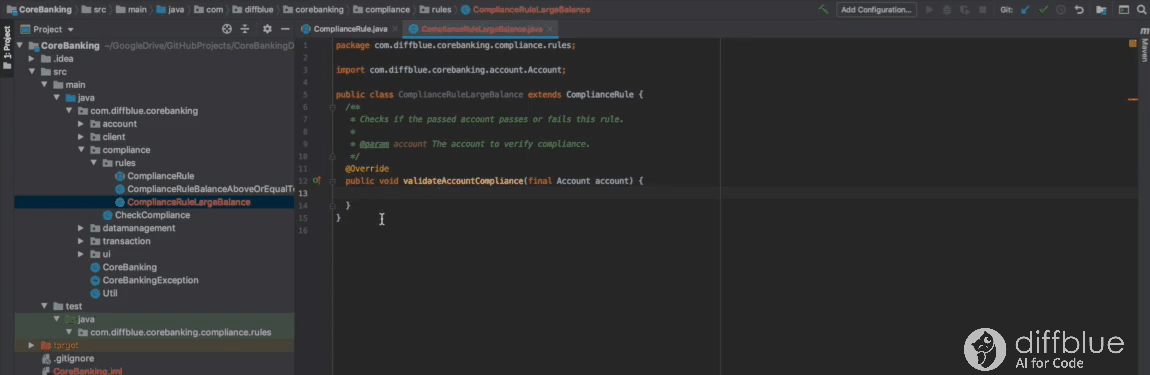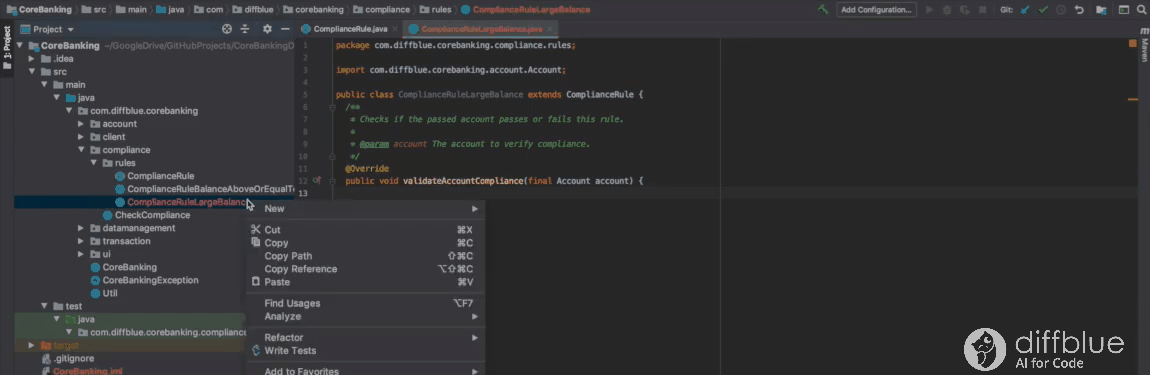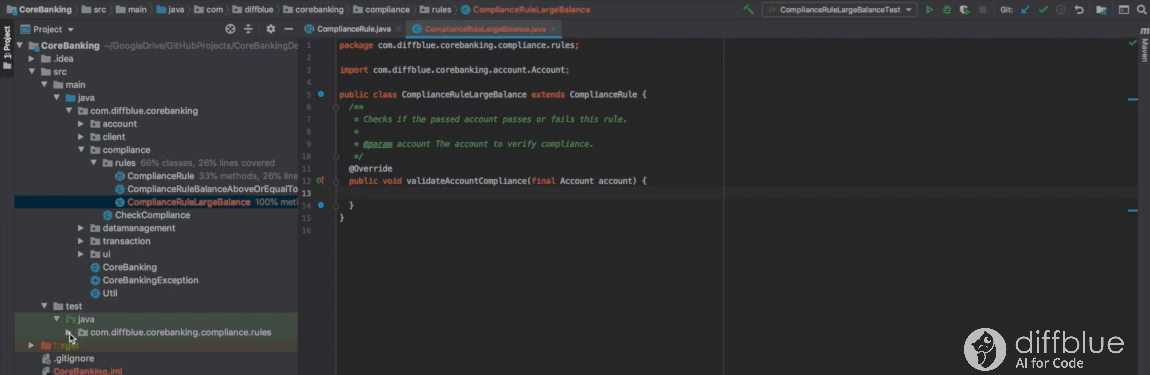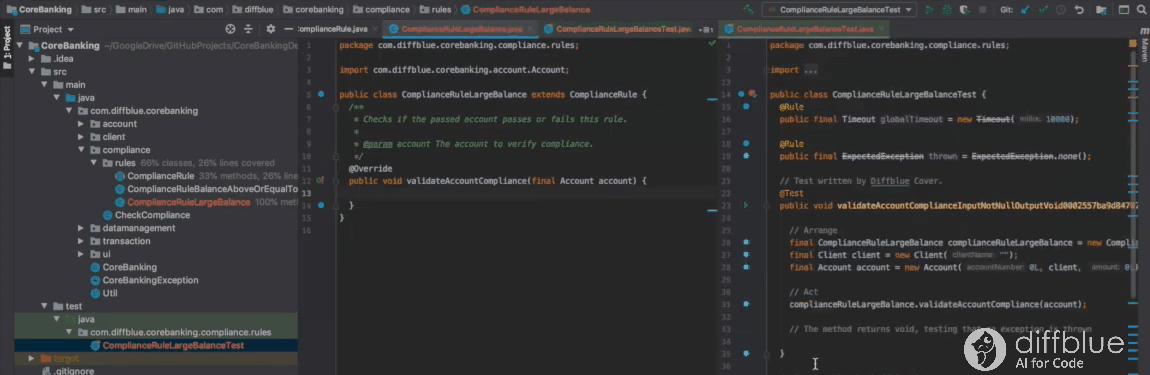
Using Cover IntelliJ plug-in to write tests
The software is not foolproof as in it doesn’t identify bugs in the source code. It assumes that the code is working correctly when the tests are added in, so if there is incorrect logic in the code it won’t be able to help you. On the other hand if the original logic was correct then it will let you know if the changes made break any of the existing functionality.
Lodge acknowledged the problem, telling us: “The code might have bugs in it to begin with, and we can’t tell if the current logic that you have in the code is correct or not, because we don’t know what the intent is of the programmer, and there’s no good way today of being able to express intent in a way that a machine could understand.
“That is generally not the problem that most of our customers have. Most of our customers have very few unit tests, and what they typically do is have a set of tests that run functional end-to-end tests that run at the end of the process.”
Lodge’s argument is that if you start with a working application, then let Cover write tests, you have a code base that becomes amenable to high velocity delivery. “Our customers don’t have any unit tests at all, or they have maybe 5 to 10 per cent coverage. Their issue is not that they can’t test their software: they can. They can run end-to-end tests that run right before they cut a release. What they don’t have are unit tests that enable them to run a CI/CD pipeline and be able to ship software every day, so typically our customers are people who can ship software twice a year.”
The software is currently only compatible with Java & IntelliJ but work is ongoing to incorporate other coding languages & IDEs.
Thanks to Theregister.com for the link to the initial story.
– Suramya