I have talked about how my Backup strategy has evolved over the years. I am quite happy with the setup I explained in my previous post except for one minor point. I still had to manually sync the data from my laptop, Jani’s laptop and my phone to my desktop manually. Once it is there on the desktop the various backup processes make sure that it is backed up and secure. The issue is that I still had to manually sync the data between the devices.
For my laptop, I used Unison to manually check for changes and then sync them over which works great but I had to ensure that the sync happened in the correct direction. For Jani’s laptop I mounted my drive on her computer over ssh using these steps and then running robocopy to copy the files over. This worked intermittently well. For some reason the system would refuse to overwrite changed files randomly with permission denied errors even when the permission was set to 777. The only way to fix was to delete all the files on my computer and then do a fresh sync. This worked, but was not userfriendly and required me to manually kick off a backup which I did infrequently. My phone on the other hand was backed up manually to my computer using sftp. This was very crumbersome and I really disliked having to do it.
I have in the past looked into various technologies that allow multiple devices to sync data with each other. Unfortunately, all of them required an external connection with a copy of the data being stored in the cloud. Since that was a show-stopper for me, I never got around to setting up my systems to automatically sync with each other. Then a few weeks ago, I came across this great article on how to create A Simple, Delay-Tolerant, Offline-Capable Mesh Network with Syncthing (+ optional NNCP). In the article John talked about Syncthing, which allowed him to create a local serverless, peer-to-peer, open source alternative to Dropbox that allowed his machines sync directly with each other without a server. In other words a perfect fit for what I wanted and needed to do. So I spent a little bit of time researching syncthing and then decided to take the plunge and setup my laptop and desktop to sync with each other. Before starting the setup I backed up all my data so that in case something went wrong I still had a backup. Thankfully nothing did, but it is always good to have a backup.
Syncthing’s installation is pretty simple for all major operating systems, except for iPhones which are not supported. In Debian, installation just required the following steps
- Run the following commands to add the “stable” channel to your APT sources:
echo "deb https://apt.syncthing.net/ syncthing stable" | sudo tee /etc/apt/sources.list.d/syncthing.list
curl -s https://syncthing.net/release-key.txt | sudo apt-key add -
Once you have added it, run the following command to install syncthing
sudo apt-get update
sudo apt-get install syncthing
Once the software is installed execute the syncthing binary. On my computer it is installed in /usr/bin/syncthing. Once the software starts, it will start the web interface automatically. There is also a Desktop application, but I prefer the web-ui. Instructions on how to configure the folders and nodes are available at the Getting Started Guide over on the project website so I am not going to repeat them here. Basically, you need to define the nodes and connect them to each other, if the devices are not added on both sites then the folders will not sync.
The software has a cool feature of discovery, which makes it easy to add devices on a given node. As soon as you connect to the same network they detect each other and give you the option of connecting both. After the devices are connected, you configure the folder you want to sync and select the devices you want it synced with. The best part is as soon as you configure one node, the other nodes will get a message stating that Node 1 is attempting to share a folder with them. Clicking on accept, allows you to configure the folder path etc on the node and that’s it. The system will detect the files which need to get synced over and will copy them quickly. You can configure the sync to be bi-directional or one way. Most of the folders in my setup are set as that, the only exception are Jani’s files which is a one-way sync because I know that I am not going to modify the files on the server.
Below is what the setup looks on my desktop, as you can see I am syncing data from 3 different computers/phones to it and the sync’s are really fast. I have copied files over to the folder on one computer and within minutes (depending on the size) they were replicated on the other computers/phone.
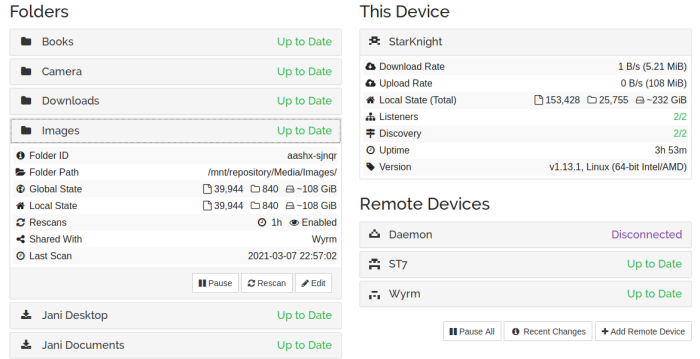
My Syncthing setup
I have the android client running on my phone as well, and it instantly syncs any new photos etc from my phone to the desktop. All I need to do is connect to the same LAN network (can be over wired or wireless) and the devices connect and sync automagically. There is an option to do so even over the WAN using relay server but since I didn’t want that I disabled it in the setup.
Now all my data is synced to the desktop machine without me having to worry about anything or manually copying files around. Check it out if you want to sync your devices without using an external server.
– Suramya




