I am a firm believer in backing up my data, some people say that I am paranoid about backing up data and I do not dispute it. All my data is backed up on multiple drives and locations and still I feel that I need additional backup. This is because I read the news and there have been multiple cases where people lost their data because they hadn’t backed it up. Initially I wasn’t that serious about it but when I was in college and working at the helpdesk, a phd student came in crying because her entire PHD thesis was on a Zip Drive and it wasn’t working anymore. She didn’t have a backup and was basically screwed. We tried a bunch of stuff to recover the data but didn’t manage to recover anything. That made me realize that I needed a better backup procedure so started my journey in creating recoverable backups.
My first backup system was a partition on my drive called backup where I created a copy of all my important data (This is back in 2000/2001). Then I realized that if the drive died then I would loose access to the backup partition as well, and I started looking for alternatives. This is around the time when I had bought a CD Writer so all my important data was backed up to CD’s and I was confident that I could recover any lost data. Shortly afterwards I moved to DVD’s for easier storage. However, I didn’t realize till a lot later that CD’s & DVD’s start becoming unreadable quite easily. Thankfully I didn’t loose any data but it was a rude awakening to find that the disks I had expected to keep my data safe were starting to become unreadable within a few years.
I then did a bunch of research online and found that the best medium for storing data long term is still Hard Drives. I didn’t want to store anything online because I want my data to be in my control so any online backup system was out of the question. I added multiple drives to my desktop and started syncing the data from the desktop & laptop to the backup drive using rync. This ensured that the important data was in three locations at any given time: My Desktop, My Laptop and the Backup drive. (Plus a DVD copy that I made of all my data every year)
I continued with this backup strategy for a few years but then realized that I had no way to go back to a previous version of any given document, if I deleted a file or wanted to go back to an older version of a file I only had 24 hours before the changes were synced to the backup drive before it was unrecoverable. There was a case where I ended up having to dig through my DVD backups to find the original version of a file that I had changed. So I did a bit of research and found rdiff-backup. It allows a user to back up one directory to another and generates an incremental backup. So we can recover/restore files based on date range. The best part is that the software is highly efficient, once the initial backup is done it only transmits the changes to the files in subsequent runs. Now that I have been using it I can restore a snapshot of my data going back to 2012 quite easily.
I was quite happy with this setup for a while, but while reading an article on best backup practices I realized that I was still depending only on 1 location for the backup data (the rdiff-data snapshots) and the best practices stated that you should also store it in an external drive or offsite location to prevent viruses/ransomware from deleting backups. So I bought a 5TB external drive and created an encrypted partition on the same to store all my important data. But I was still unhappy because all of this was still stored at my home so if I had a fire or something I would still end up loosing the data even though my external drive was kept in a safe. I still didn’t want to store data online but that was still the best way to ensure I had offsite backup. I initially thought about setting a server at my parents place in Delhi and backup there but that didn’t work out for various reasons. Plus I didn’t want to have to call them and troubleshoot backup issues over the phone.
Around this time I was reading about encrypted partitions and came up with the idea of creating an encrypted container file to store my data and then backup the container file online. I followed the steps I outlined in my post How to encrypt your Hard-drive in Linux and created the encrypted container. Once I finished that I had to upload the container to my webhost since I had unlimited storage space as per my contract. Initially I wasn’t able to because they had restricted my account’s quota but a call to their customer support sorted it out after a bit of argument and explaining what I was doing. The next hurdle I faced was uploading the file to the server because of the ridiculously low upload speed I was getting from Airtel. I had a 40 mbps connection at the time but the upload speed was restricted to 1 mbps because of ‘reasons’. After arguing with their support for a while, I was complaining about it at work and one of the folks suggest I check out ACT Internet. I checked out their plans and was quite impressed with the offerings so I switched over to ACT and was able to upload the container file quickly and painlessly.
Once the container was uploaded, I had to tackle the next problem in the process which was on how to update the files in the container without having to upload the entire container to the host. I experimented with a few solutions and then came up with the following solution:
1. Mount the remote partition as a local mount using sshfs. I mounted the partition locally using the following command: (please replace with the correct hostname and username before using)
/usr/sbin/runuser -l suramya -c "sshfs -o allow_other @hostname.com:. /mnt/offsite/"
2. Once the remote partition was mounted locally, I was able to use the usual commands to mount the encrypted partition to another location using the following command:
/usr/sbin/cryptsetup luksOpen /mnt/offsite/container/Enc_vol1.img enc --key-file /root/UserKey.dat
mount /dev/mapper/enc /mnt/stash/
In an earlier iteration of the code I wasn’t using the keyfile so had to manually enter the password everytime I wanted to backup to the offsite location. This meant that the backup was done randomly as and when I remembered to run the command manually. A few days ago I finally configured it to run automatically after adding the keyfile as a decryption key. (Obviously the keyfile should be protected and not be accessible to others because it allows users to decrypt the data without entering a password.) Now the offsite backup runs once a week while the local backup runs daily and I still backup the Backup partition to the external drive as well manually as and when I remember to do so.
In all I was quite happy with my setup but then I was updating the encrypted container and a network issue made be believe that my remote container had become corrupted (it wasn’t but I thought it was). At the same time I was fooling around with Microsoft One Drive and saw that I had 1TB of storage available over there since I was a Office 365 subscriber. This gave me the idea of backing up the Container to OneDrive as well as my site hosting.
I first tried copying the entire container to the drive and hit a limit because the file was too large. So I thought I would split the file into 5GB parts and then sync them to OneDrive using rclone. After installing rclone. I configured it to connect to OneDrive by issuing the following command and following the onscreen prompts:
rclone config
I then created a folder on OnDrive called container to store the split files and then tried uploading a test file using the command:
rclone copy $file OneDrive:container
Where OneDrive is the name of my provider that I configured in the previous step. This was successful so I just needed to create a script that did the following:
1. Update the Container file with the latest backup
2. Split the Container file into 5GB pieces using the following command:
split --verbose -d -b5GB /mnt/repository/Container/Enc_vol1.img /mnt/repository/Container/Enc_vol_
3. Upload the pieces to Ondrive.
for file in `ls /mnt/repository/Container/Enc_vol_* |sort`; do echo "$file"; /usr/bin/rclone copy $file OneDrive:container -v &> /tmp/oneDriveSync.log; done
This command uploads the pieces to the drive one at a time and is a bit slow because it maxes out the upload speed to ~2mbps. If you split the uploads and run the command in parallel then you get a lot faster speed. Keep in mind that if you are uploading more than 10 files at a time you will start getting errors about too many open connections and then you have to wait for a few hours before you can upload again. It took a while to upload the chunks but now my files are stored in yet another location and the system is configured to sync to Onedrive once a month.
So, as of now my files are backed up as following:
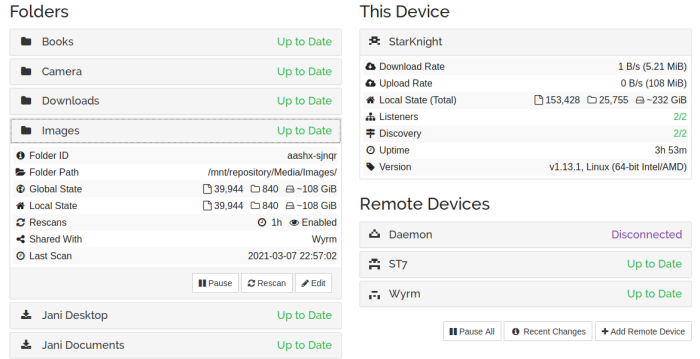
- /mnt/Backup: Local Drive. All changes are backed up daily using rdiff-backup
- /mnt/offsite: Encrypted Container stored online. All changes are backed up weekly using rsync
- OneDrive: Encrypted Container stored at Microsoft OneDrive. All changes are backed up monthly using rsync
- External Drive: Encrypted backup stored in an External Hard-drive using rsync. Changes are backed up infrequently manually.
- Laptop: All Important files are copied over to the laptop using Unison/rsync manually so that I can access my data while traveling
Finally, I am also considering backing up the snapshot data to BlueRay disks but it will take time so haven’t gotten around to it yet.
Since I have this elaborate backup procedure I wasn’t worried much when one of my disks died last week and was able to continue work without issues or worries about loosing data. I still think I can enhance the backups I take but for now I am good. If you are interested in my backup script an extract of the code is listed below:
function check_failure ()
{
if [ $? == 0 ]; then
logger "INFO: $1 Succeeded"
else
logger "FATAL: Execution of $1 failed"
wall "FATAL: Execution of $1 failed"
exit 1
fi
}
###
# Syncing to internal Backup Drive
###
function local_backup ()
{
export BACKUP_ROOT=/mnt/Backup/Snapshots
export PARENT_ROOT=/mnt/repository
logger "INFO: Starting System Backup"
rdiff-backup -v 5 /mnt/data/Documents/ $BACKUP_ROOT/Documents/
check_failure "Backing up Documents"
rdiff-backup -v 5 /mnt/repository/Documents/Jani/ $BACKUP_ROOT/Jani_Documents/
check_failure "Backing up Jani Documents"
rdiff-backup -v 5 $PARENT_ROOT/Programs/ $BACKUP_ROOT/Programs/
check_failure "Backing up Programs"
..
..
logger "INFO: All Backups Completed Successfully."
}
###
# Syncing to Off-Site Backup location
###
function offsite_backup
{
export PARENT_ROOT=/mnt/repository
# First we mount the remote directory to local
logger "INFO: Mounting External Drive"
/usr/sbin/runuser -l suramya -c "sshfs -o allow_other username@remotehost:. /mnt/offsite/"
check_failure "Mounting External Drive"
# Open the Encrypted Partition
logger "INFO: Opening Encrypted Partition. Please provide password."
/usr/sbin/cryptsetup luksOpen /mnt/offsite/container/Enc_vol1.img enc --key-file /root/keyfile1
check_failure "Mounting Encrypted Partition Part 1"
# Mount the device
logger "INFO: Mounting the drive"
mount /dev/mapper/enc /mnt/stash/
check_failure "Mounting Encrypted Partition Part 2"
logger "INFO: Starting System Backup"
rsync -avz --delete /mnt/data/Documents /mnt/stash/
check_failure "Backing up Documents offsite"
rsync -avz --delete /mnt/repository/Documents/Jani/ /mnt/stash/Jani_Documents/
check_failure "Backing up Jani Documents offsite"
..
..
..
umount /mnt/stash/
/usr/sbin/cryptsetup luksClose enc
umount /mnt/offsite/
logger "INFO: Offsite Backup Completed"
}
This is how I make sure my data is backed up. All of Jani’s data is also backed up to my system using robocopy as she is running Windows and then the data gets backed up by the scripts I explained above as usual. I also have scripts to backup my website/blog/databases but that’s done using a simple script. Let me know if you are interested and I will share them as well.
This is all for now. Let me know if you have any questions about the backup strategy or if you want to make fun of me. 🙂 This is all for now. Will write more later.
– Suramya