
...making Linux just a little more fun!
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from Benno Schulenberg <bensberg@justemail.net> -----
Date: Sat, 17 May 2008 14:56:19 +0200 From: Benno Schulenberg <bensberg@justemail.net> Subject: lang="utf-8" makes Firefox use an ugly font To: editor@linuxgazette.net
Hello editor,
In the source of many of the HTML pages of the Linux Gazette, the <HTML> tag contains 'lang="utf-8" xml:lang="utf-8"'. This has the effect of making Firefox think that this is some exotic language, and it falls back to a simple, smaller, uglier, unaliased font. For example on http://linuxgazette.net/150/index.html .
On http://www.w3.org/TR/xhtml1/ the W3 suggests that the <HTML> tag contain 'xml:lang="en" lang="en"'. When I replace the existing attributes with these, then the page gets shown fine for me.
(The possible reason that only I see this problem is that I've set Firefox to always use my chosen font, and ignore the fonts of the website. This works fine on almost all Web sites. Only on Japanese sites and on Linux Gazette do I still get this ugly unaliased font.)
Regards,
Benno
----- End forwarded message -----
[ Thread continues here (6 messages/7.75kB) ]
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from "Triyan W. Nugroho" <triyan.wn@gmail.com> -----
Date: Fri, 16 May 2008 02:21:54 +0800 From: "Triyan W. Nugroho" <triyan.wn@gmail.com> To: editor@linuxgazette.net Subject: Linux Gazette IndonesiaHi guys,
I would like to announce that Linux Gazette Indonesia has been moved to its new home, http://linuxgazette.ailabs.web.id.
This project is still low in progress, and still considered as a personal project, which is updated only in my spare time. Anyone who is interested to join, please let me know. I will be very happy to proofread and publish your translation.
I hope this little contribution will give benefit to the community, especially for Indonesian people right here.
Best regards,
Triyan W. Nugroho
Linux Gazette Indonesia
----- End forwarded message -----
[ Thread continues here (2 messages/2.25kB) ]
Amit k. Saha [amitsaha.in at gmail.com]
Hello all,
I have installed Ubuntu 8.04 (32-bit) beta on my 32-bit notebook and Ubuntu 8.04 (64-bit) on a friend's 64-bit laptop. I am using Acer laptops.
In both cases, using the touchpad to click (single/double-click) is pretty troublesome, and needs a rather "hard" hit on the pad. I have tried setting the mouse preferences similar to the one on Ubuntu 7.04 (which I use), but to no avail.
Any hints?
Regards, Amit
-- Amit Kumar Saha
[ Thread continues here (3 messages/3.46kB) ]
Ben Okopnik [ben at linuxgazette.net]
Forwarding this exchange between Rick and myself, with his explicit permission - an interesting bit of info on the Licensing Wars.
Rick Moen wrote:> Quoting Ben Okopnik (ben@linuxmafia.com): > > > Hey, Rick - > > > > I've just been contacted by these people: > > > > http://www.openinventionnetwork.com/ > > > > They want to write something for us. [ ... ] What's your take on this? > > They're legit. I think the main reason they smell funny is that their > main assets -- the reason for their existence, a set of software patents > -- inherently smells funny. > > Back in the 1990s, there was a firm called Commerce One, which through > acquisitions picked up a bunch of patents related to online > communications, mostly business-to-business and e-commerce stuff. They > filed for bankruptcy protection in 2004, and the court approved a sale > of the patent portfolio to a subsidiary of Novell. > > My impression is that Novell at that point woke up and said "We just > acquired what?" They really didn't want to become patent barons, and > saw from the SCO fiasco that they wanted to keep clear of, and > preferably disarm, the more scumsucking elements of the "intellectual > property" ranching business. So, they talked with IBM, Philips, Red > Hat, and Sony, and got them all to pitch in patents and money to launch > Open Invention Network to hold contributed patents (including the > Commerce One portfolio) and licence them royalty-free to any firm that > in return promises patent peace towards Linux and a list of > Linux-related codebases (Apache, Eclipse, Evolution, Fedora Directory > Server, Firefox, GIMP, GNOME, KDE, Mono, Mozilla, MySQL, Nautilus, > OpenLDAP, OpenOffice.org, Open-Xchange, Perl, PostgreSQL, Python, Samba, > SELinux, Sendmail, and Thunderbird). > > There's not a lot that stands absolutely in the way of them turning > evil, but it's reassuring that Red Hat's Mark Webbink approves of them > highly. See: http://www.dwheeler.com/blog/2006/04/14/#oin > > I hate to lose my cynic credentials, but I'd say you should eagerly > invite an article submission! >
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (3 messages/8.08kB) ]
Ben Okopnik [ben at linuxgazette.net]
http://www.ted.com/talks/view/id/247
First I've ever heard of Yochai Benkler (http://en.wikipedia.org/wiki/Yochai_Benkler); fascinating perspective, and a really good answer to the perennial "but where's the money in that stuff?" Heady wine for anyone desperately trying to get a clue about where we're going with this stuff, too.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
Ben Okopnik [ben at linuxgazette.net]
Yeah, it's all the news now, so I figured I'd kick in my bit. 
As those of you on staff are aware, we use SSH keyauth for our staff
accounts. I've been running some checks for weak keys (for any of you
that want to check your own,
http://security.debian.org/project/extra/dowkd/dowkd.pl.gz is a
detector), and - whoops! We had a few in the list. Gone now, of course.
(Amit, please revise your keys and send them to me.
We now return you to your scheduled programming.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (15 messages/19.78kB) ]
Deividson Okopnik [deivid.okop at gmail.com]
Anyone tried Hardy Heron (Ubuntu) yet?
I just installed Hardy on my new machine, first Linux distro on that machine, and I couldn't get my network to work. I dual-boot (with XP) and, on WinXP, it's working OK. My network is pretty simple - each machine has its own static IP (no DHCP). On Hardy, I configured the IP via the network config (the same IP I use on that machine for Windows XP), but nothing works. I can't ping other machines on the network, other machines can't ping me, and Hardy is not asking for any driver or anything.
Any clue on what could I check to try to solve that problem?
[ Thread continues here (10 messages/13.21kB) ]
Jim Jackson [jj at franjam.org.uk]
[[[ This is a followup to a discussion in issue 150. http://linuxgazette.net/150/misc/lg/sendmail_and_capacity.html -- Kat ]]]
> I strongly suspect that it was a case of "Works Fine For Me".
And in similar vein, how many Web sites load and look OK when demo'd on a LAN but suck to high heaven when accessed over ADSL, never mind a dialup connection! But you can't legislate against stupidity.
[ In reference to "Laptop review: Averatec 5400 series" in LG#108 ]
John Karns [johnkarns at gmail.com]
On Wed, Apr 23, 2008 at 11:23 AM, Rick Moen <rick@linuxmafia.com> wrote:
> Quoting Ben Okopnik (ben@linuxgazette.net): > > > I'd like to correct one common misapprehension, though: you don't have > > to learn to program in order to use Linux. in fact, the skills you need > > to use it are the same ones that you need for using Windows. > > Actually, I think it's time we counter the hoary "you have to be a > programmer to use Linux" farrago with a far more credible counter-meme: > You really must be a programmer to stand a chance of not being > horribly frustrated by MS-Windows. > > Consider how many times we've heard from MS-Windows users that the poor > security architecture, corruption-prone registry, spyware-infested > proprietary software marketplace, fragile and fragmentation-tending > filesystems, and so on have driven them to utter distraction.
So true! My sister just told me how she had recently suffered the loss of all the data on her laptop, collected over at least three years. It was all due to a family member visiting a Web site that infected the system with some kind of virus. Her comment to me was something like "I just hate computers!" My retort was the usual "The problem is not inherent to 'computers', but MS Windows's inferior design. You really ought to have Linux installed."
It's really sad when there is not even the slightest awareness that the monopoly OS is not the only choice available.
Unfortunately, she and her spouse are at a total loss as to how to approach it, other than calling the Geek Squad to re-install the inferior system, and wait for it to happen all over again sometime in the future.
-- John
[ Thread continues here (7 messages/10.88kB) ]
[ In reference to "A Question Of Rounding" in LG#143 ]
René Pfeiffer [lynx at luchs.at]
Hello!
Last week I bought the third edition of the "Numerical Recipes" (http://www.nr.com/). I first used this book over ten years ago when coding mathematical functions for a calculator software on the Commodore Amiga. The third edition has more sections and more code in it. Today the section 22.2 caught my eye. The title is "Diagnosing Machine Parameters". It deals with the problems of floating-point arithmetic and mentions the fact that IEEE 754 has the advantage of being defined and known. A lot of older computing hardware had their own floating-point representation with varying parameters.
The section introduces a piece of code for measuring these machine parameters. It's called MACHAR, and published here: http://portal.acm.org/citation.cfm?id=3D51907&dl=3DACM&coll=3Dportal
"Numerical software written in high-level languages often relies on machine-dependent parameters to improve portability. MACHAR is an evolving FORTRAN subroutine for dynamically determining thirteen fundamental parameters associated with a floating-point arithmetic system. The version presented here operates correctly on a large number of different floating-point systems, including those implementing the new IEEE Floating-Point Standard."
C source can be found here for example: http://www.netlib.org/blas/machar.c
Just to let you know.
Best,
René.
[ In reference to "Virtualizing without Virtualizing" in LG#150 ]
Jim Dennis [answrguy at gmail.com]
Kapil forgot at least one important term in his "EULA(1)":
* The software to be run can share the network interface state with the parent and all siblings.
In particular we have have to recognize that only one process (family) on a given machine can bind to a given port to accept incoming requests. For example, you can only have one sshd listening on port 22 on any given interface, and one listening on the "catchall" interface. If I have one sshd listening on the catchall and one listening on the address bound eth0:0 (both on TCP port 22), then any incoming request for that one address will go to the second process; any other incoming requests will go to the first one.
(It's fairly rare to configure a system with a mixture of processes listening on specific and catchall addresses, BTW; but it is possible).
The key point here is that the chroot "virtualization" is not amenable to hosting networking services, unless you can arrange some way to dispatch the incoming connections to their respective chroot jailed processes on different ports or IP aliases.
However, overall I have been recommending chroot as a "super lightweight virtualization" model for many years. It only virtualizes the file/directory structure, but that's often sufficient to development work, for example.
JimD (AnswerGuy emeritus?)
[ Thread continues here (5 messages/6.07kB) ]
[ In reference to "Measuring TCP Congestion Windows" in LG#136 ]
René Pfeiffer [lynx at luchs.at]
On May 06, 2008 at 2343 +0530, akshay saad appeared and said:
> On Tue, May 6, 2008 at 5:31 PM, René Pfeiffer <lynx@luchs.at> wrote: > > On May 06, 2008 at 0020 +0530, akshay saad appeared and said: > > > Hi, > > > I was following your article http://linuxgazette.net/136/pfeiffer.html > > > (Measuring TCP congestion window). > > > What I observed was that RTT is constant throughout the experiment I > > > did with your code . > > > I was wondering isn't it suppose to change ? > > > > It depends on your test environment. What was the network link between > > the two hosts? If it was a local link (such as Ethernet) the RTT won't > > change much. You need a WAN link (simulated or real) to observe RTT > > variations. Unsaturated links don't produce very little RTT variations. > > > I did tried that on intercontinental network. But I can access > network only through proxy server of my college. Does that create a > difference ?
Yes, a proxy effectively cuts the TCP connection in two. You have one connection from the client to the proxy, and one from the proxy to the server. The RTT you are observing is the one between you and the proxy server of your college. This may be the reason why there are no variations.
Best,
René.
[ In reference to "Knoppix 5.3.1" in LG#150 ]
R.+F. Weggler-Willi [weggler.willi at bluewin.ch]
Hi Edgar
I absolutely agree with you about "compiz". I do not see any advantages for me with firing disappearing windows! So the best new cheatcode for Knoppix 5.3.1 is
=> "no3d".
... but let taste be taste. Knoppix 5.3.1 is really the most mature live-CD available. Thanks to Klaus and the Debian people.
Bob Weggler
[ In reference to "Lockpicking" in LG#150 ]
Frederik Deweerdt [deweerdt at free.fr]
Hi,
I enjoyed the article on deadlock detection. I wanted you to know that I developed a library and utility that do basically the same thing. One notable difference is that hierarchical trees of locks are built at the run time.
The code is GPL and available from here: http://www.ohloh.net/projects/6739
Regards,
Frederik
[ Thread continues here (3 messages/2.94kB) ]
[ In reference to "2-Cent Tips" in LG#150 ]
clarjon1 [clarjon1 at gmail.com]
<snip>
> > > > And, finally, corrupted ISO downloads. A friend taught me how to fix > > > these: If your ISO is corrupted, it seems like all you have to do to fix > > > it is to create/get a torrent of it, stick the corrupted download in the > > > directory where the ISO will be downloaded to by default, and let the > > > torrent system correct it for you! > > > > I can't see this working at all. Were you told this on April 1st? ;) > > I was, now that I go through my chat logs, but the person who asked me about > whether or not I had the file handy for a torrent, and introduced me to this, > had previously posted for help for the image he was requesting, a few days > before.
Just found this on Slashdot, for all those who are still unbelievers...
http://tech.slashdot.org/tech/08/05/04/2230252.shtml
-- clarjon1
Thomas Bonham [thomasbonham at bonhamlinux.org]
Hi All,
Here is a 2-cent tip that is a little Perl script for looping through directories.
#!/usr/bin/perl
# Thomas Bonham
# Create on 05/27/2008
# Function is for list all contents of a directory
use Cwd;
sub searchdir
{
my $dir = shift;
my $cwd = getcwd();
if ($dir ne "") {
unless (chdir($dir)) {
print STDERR "Unable to chdir to $cwd/$dir: $!\n";
return;
}
}
opendir(DIR, ".");
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file eq "." || $file eq "..";
if (-d $file) {
searchdir($file);
next;
}
# Do what you would like here
print getcwd(),"/",$file,"\n";
}
chdir($cwd);
}
sub main() {
searchdir();
}
main();
Thomas
[ Thread continues here (2 messages/1.68kB) ]
Jonathan Clark [clarjon1 at gmail.com]
This tip goes out to all the students who use Linux, with Compiz-Fusion...
How many students have been working on something, like, for example, updating their software, or checking their e-mail, or getting tech support on IRC, when a teacher walks up, glances at your screen, and gasps because "That's not school work! You, you must be Hacking the system!!"
*raises hand*
Thanks to Compiz-fusion, I've been able to avoid this with even the most... shall we say obstinate? teachers out there...
As some of you may know, Compiz-Fusion allows one to reduce the opacity of individual windows by using <Alt>+<ScrollWheelDown>, and restore the opacity with <Alt>+<ScrollWheelUp>.
However, some may not be fooled... Not to worry, you can make it look like it's a part of your desktop background...
Open up the CompizConfig util, and activate the Freewins plugin. Press <Ctrl>+<Shift>, click in the window you want to make more hidden, and move the mouse around. Your window has... rotated! Press <Ctrl>+<shift>+<MouseButton3> or <MouseButtons1and2simultaneiously> to return the window to its proper rotation. The only drawback currently with this rotated window is that the inputs, like text input boxes, menus, buttons, even the window decorations, still expect the mouse clicks to be where the items are supposed to be when the window is non-rotated.
Hope this makes for some more happy Linuxing!
Of course, the best way to keep from getting into trouble, is to do your work in class. And not goof off. But, if you're using Linux, and it looks different from what some teachers expect, no amount of explaining will keep you out of their "watchlists". Been there, done that. Even had to explain to the principal (!!) that I wasn't doing anything wrong. That was not a Good Day...
-- Clarjon1 Proud Linux User. PCLinuxOS on Dell Inspiron 1501, 1 Gig RAM, 80 Gig hard drive 1.7GHz AMD Athlon 64bit dualcore processor Contact: Gmail/gtalk: clarjon1 irc: #pclinuxos,#pclinuxos-support,##linux on freenode QOTD:
Mulyadi Santosa [mulyadi.santosa at gmail.com]
Tired of script-generated logs cluttered with escape characters all over the place
Try to change the terminal into "dumb" and repeat:
$ export TERM=dumb $ script <do whatever necessary to be logged> <type exit or press Ctrl-D> $ export TERM=xterm Switch back to vt100, xterm, or other when you're done, to recover your terminal's original mode.Observe the generated log:
$ cat -A typescript mulyadi@mushu:/tmp$ ls^M$ gconfd-mulyadi^I^I mc-mulyadi^I ssh-tYecBM5768^M$ gedit.mulyadi.3088662139 orbit-mulyadi Tracker-mulyadi.5855^M$ keyring-HzVeHi^I^I plugtmp^I typescript^M$ mapping-mulyadi^I^I sqlGIskW0^I virtual-mulyadi.SGmoJb^M$
Note that we see ^I, ^M, and so on because of the -A option on "cat". This is needed, so we are sure there are no escape characters there.
[ Thread continues here (11 messages/13.12kB) ]
Ben Okopnik [ben at linuxgazette.net]
I saw a Web page the other day, talking about a cute idea: since the spammers are always trawling the Net for links and e-mail addresses, why not give them some nice ones? For a certain value of "nice", that is...
However, when I looked at the implementation of this idea, the author had put a "badgeware" restriction on using it - not something I could see doing - so I wrote a version of it from scratch, with a few refinements. Take a look:
http://okopnik.com/cgi-bin/poison.cgi
A randomly-generated page, with lots of links and addresses - with the links all pointing back to the script itself (somewhat obscured, so they don't look exactly the same), so the spammers can harvest even more of these addresses. Mmm, yummy!
The addresses are made up of a random string "at" a domain made up of several random words joined together with a random TLD. There is some tiny chance of it matching a real address, but the probability is pretty low.
If you want to download this gadget, it's available at
http://okopnik.com/misc/poison.cgi.txt (and, once the next issue of LG
comes out, at 'http://linuxgazette.net/151/misc/lg/poison.cgi.txt'.) I
suggest renaming it to something else , and linking to it - the link
doesn't have to be visible [1] - from a few of your real Web pages. If
enough people started doing this, life would become a lot more pleasant.
Well, not for spammers, but that's the whole point...
[1] '<a href="poison.cgi" border="0"> </a>' at the end of a page should be invisible but still serve the purpose.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (3 messages/4.57kB) ]
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to bytes@linuxgazette.net.
![[lightning bolt]](../gx/bolt.gif) Wind River joins forces with Intel on Auto Linux
Wind River joins forces with Intel on Auto Linux
Wind River and Intel hope to dramatically disrupt the automotive industry's in-vehicle infotainment market, introducing open source solutions to challenge the current proprietary approach currently taken by the auto industry.
The two companies have collaborated to create an open source Linux platform optimized for Intel's tiny new Atom processor. The specifications and the code from the platform will be released by Wind River to the open source community via Moblin.org.
Wind River also unveiled a platform based on an automotive-optimized commercial Linux. The Wind River Linux Platform for Infotainment is optimized for Atom, and offers integration with many leading third-party networking and multimedia applications, including speech-recognition technologies by Nuance Communications; Bluetooth and noise reduction solutions by Parrot; music management technologies by Gracenote; multimedia networking solutions by SMSC; and DVD playback by Corel's LinDVD.
This approach will enable the development of Open Infotainment Platforms that are based on interoperable, standards-based hardware and software components. This will allow manufacturers to scale software across devices, leading to cost and development efficiencies.
Wind River expects to deliver the open source specification and code to the Moblin.org in-vehicle infotainment community in August 2008.
Companies such as BMW Group, Bosch, Delphi and Magneti Marelli are actively supporting Wind River's strategy to drive Linux into the automotive market. Wind River already plays a leading role in collaborating with industry consortia aimed at developing open, Linux-based software platforms, namely: Eclipse, SCOPE-Alliance, OpenSAF, The Linux Foundation, LiMo Foundation and Open Handset Alliance.
For further information about Wind River's and Intel's open source efforts, visit http://opensource.windriver.com.
First Moonlight Release Moonlight, the open-source alternative to Microsoft's Silverlight,
(Wikipedia entry)
has released its first efforts for anyone interested in contributing to
the project. While it is not ready-to-use yet, this is the first step into
inserting Silverlight into Linux by utilizing Mono.
http://tirania.org/blog/archive/2008/May-13-1.html
NetBeans Community Links to PHP Community with NetBeans Early Access for PHPAt CommunityOne 2008 in May, Sun Microsystems and the NetBeans community announced NetBeans IDE 6.1 General Availability and the NetBeans IDE Early Access for the PHP scripting language, bringing the power of NetBeans to Web 2.0 developers. A download is available at http://www.netbeans.org.
NetBeans IDE Early Access for PHP includes intelligent editing features such as prioritized code completion, instant rename, mark occurrences, dynamic code templates, and easy navigation. Besides the editor, it provides debugging support, deployment to the local server, dynamic help, and sample projects making it easier to get started with PHP development. It also provides support for embedded CSS, HTML and JavaScript(TM) technologies. More details can be found here: http://www.netbeans.org/features/web/web-app.html
NetBeans evangelist Gregg Sporar told Linux Gazette: "The Early Access version of NetBeans support for PHP supports version 5.2 of the PHP language. Our goal is to also support version 5.3 of PHP later this year when we do a final release of our PHP support. Support for PHP 6 is on our road map, but is further out."
NetBeans 6.1 IDE includes new features for developing Ajax web applications using JavaScript(TM) technology and delivers tighter integration with MySQL(TM) database.
JavaScript technology support is based on the dynamic language infrastructure added for the Ruby programming language and includes: semantic highlighting, code completion, type analysis, quick fixes, semantic checks and refactoring. Version 6.1 also adds in a browser compatibility feature that makes it easier to write JavaScript code to run in Mozilla Firefox, Opera, Safari or Windows Internet Explorer.
The NetBeans Database Explorer in NetBeans IDE 6.1 makes it easier to create, start and stop MySQL databases and to connect to and browse a database's tables. Other new NetBeans features include faster startup and code completion, enhanced support for Ruby and JRuby, including a new Ruby platform manager and support for IBM's Rational ClearCase version control system.
For a full list of features or to download the NetBeans 6.1 IDE, visit: http://www.netbeans.org.
The free NetBeans Day community track offered developers a chance to learn from the experts, find out firsthand what's new and what's coming in the NetBeans IDE and Platform and to network with other members of the community. http://developers.sun.com/events/communityone
Ubuntu Live 2008 Canceled
Ubuntu Live, the conference that was scheduled to happen on July 21th in Portland, OR has been canceled. Canonical is going to add Ubuntu content to the OSCON, that will happen in the same weekend, at the same city.
http://en.oreilly.com/ubuntu2008/public/content/home
OpenSolaris goes LiveCDAt the CommunityOne Developer Conference, Sun and the OpenSolaris community jointly announced a refreshed OpenSolaris, based on Sun's Solaris kernel and created through community collaboration. This version has many of the GNU and open source tools expected by Linux users and an enhanced package manager. Download the OpenSolaris OS now at http://www.opensolaris.com/.
"OpenSolaris ... combines the strong foundation of Solaris technologies and tools with modern desktop features and applications developed by open source communities such as GNOME, Mozilla and the Free Software Foundation," said Stephen Lau, OpenSolaris Governing Board member. "OpenSolaris provides an ideal environment for students, developers and early adopters looking to learn and gain experience with innovative technologies like ZFS, Zones and DTrace. And yes, it uses bash by default."
LiveCD installation and the new network-based OpenSolaris Image Packaging System (IPS) simplify and speed installation and integration with third-party applications. OpenSolaris IPS increases installation speed and accuracy by providing better control of applications and dependencies and offers easy-to-use system management. At a keynote demo, the LiveCD came up in about a minute. A full disk install had about 2 minutes of screens and then took 15 minutes on demo system.
The OpenSolaris OS is the first OS to feature ZFS as its default file system, protecting work with instant roll-back and continual check-summing capabilities to allow users to test ideas. Its Dynamic Tracing (DTrace) feature provides safe, pervasive observability of production systems to accelerate application development and optimization of the AMP/MARS stack. Additionally Solaris Containers can build virtualization-aware applications that can be deployed on single machines through multi-CPU and multi-core systems, without worrying if third-party software will work.
This release is called OpenSolaris 2008.5; the next major release is 2008.11 in 6 months.
HP and Novell offer Migration Program for HP Identity Management CustomersHP and Novell have formed an exclusive alliance to migrate HP Identity Center customers to Novell identity and security management solutions. As part of an agreement between the companies, HP and Novell will jointly offer migration services, HP will resell Novell identity and security management solutions and Novell will license HP Identity Center technology.
"HP and Novell have clarified a path forward for HP Identity Center customers who have invested in critical identity management infrastructure," said Gerry Gebel, vice president and service director, Burton Group. "The agreement between Novell and HP is a positive outcome for both vendors as they partner to address technology and services requirements of enterprises in an increasingly competitive industry."
"We chose to collaborate with Novell because of its outstanding set of technologies, recognized market leadership and tremendous commitment to working with HP customers," said Ben Horowitz, vice president and general manager, Business Technology Optimization, Software, HP.
The HP and Novell migration program will provide comprehensive support to customers throughout the transition process, including a license credit for first 12 months, migration services provided by the HP Consulting and Integration team and joint development of migration tools
More information about Novell identity and security management solutions is available at www.novell.com/identityandsecurity.
Concordia Project To Tackle Security Policy & Standards at Burton CatalystConference in JuneThe Concordia Project has announced a sixth face-to-face meeting on security standards taking place at Burton Group Catalyst Conference 2008 in San Diego on June 23. The public meeting is sponsored by Liberty Alliance and Burton Group and is the first Concordia event to focus on policy and entitlements management and associated standards such as XACML and WS-Policy.
The interactive session will feature representatives from Boeing, Cisco, Micron Technology and the US Army, among others, presenting use case scenarios to a Concordia technical team made up of representatives from, among others, IBM, BEA and Liberty Alliance. Registration and more information about the workshop is available at http://tinyurl.com/4dvtpa
The June 23 workshop follows the RSA Conference 2008 event where the community held its first interoperability demonstrations. Nearly 600 attended the public workshop where FuGen Solutions, Internet2, Microsoft, Oracle, Ping Identity, Sun Microsystems and Symlabs demonstrated interoperability scenarios designed to meet deployer requirements using Info Card, Liberty Alliance, and WS-* identity protocols. Previous meetings have taken place at RSA Conference 2007, Catalyst 2007, Digital ID World, the Identity Open Space (IOS) and the Internet Identity Workshop (IIW). All organizations and individuals interested in contributing to the deployment of standardized policy frameworks and proven interoperable standards-based solutions are encouraged to attend the June 23 workshop.
Join top security researchers and practitioners in San Jose, CA, for a 5-day program that includes in-depth tutorials by experts such as Simson Garfinkel, Bruce Potter, and Radu Sion; a comprehensive technical program including a keynote address by Debra Bowen, California Secretary of State; invited talks including "Hackernomics," by Hugh Thompson; the refereed papers track including 27 papers presenting the best new research; Work-in-Progress reports; and a poster session. Learn the latest in security research including voting and trusted systems, privacy, botnet detection, and more.
 Fedora 9 is Out!
Fedora 9 is Out!
Less than a month after the release of the new version of Ubuntu, and following a half-year of its own development, the Fedora Project has introduced the Fedora 9 Linux distribution, a.k.a. 'Sulfur'. This distro sports a Linux 2.6.25 kernel, Glibc 2.8, and current versions of GNOME and KDE. It also adds PackageKit, a cross-distribution package management solution.
Fedora still has a complex install and there are reported problems coexisting with other OSes, something that Ubuntu has had in hand for a while, but this is a solid release with broad hardware support.
For more information on Fedora 9 visit: http://fedoraproject.org.
Release notes are here: http://docs.fedoraproject.org/release-notes/f9/
openSUSE 11.0 Beta 3 to be lastThe openSUSE team has announced Beta 3 as the last beta release of openSUSE 11.0. Over 700 bugs have been fixed since Beta 2, including installation bugs.
The GA release of openSUSE 11 is expected mid-June.
Screenshots of 11.0 Beta 3 here: http://en.opensuse.org/Screenshots/openSUSE_11.0_Beta3Damn Small Linux v4.4RC1
DSL's first Release Candidate for the 4.4 version is out and ready for testing. More info at:
http://damnsmalllinux.org/
MEPIS antiX 7.2 released
MEPIS has announced the release of MEPIS antiX 7.2, the lightweight variant of MEPIS Linux designed for older computers.
Built using the MEPIS Linux 7.0 core, including the 2.6.22 kernel and selected additions from Debian Lenny, the lightweight operating system is appropriate for older hardware and users who like a very fast functional system. Pre-configured window managers Fluxbox and IceWM, as well as Conky and ROX Desktop, come ready to use. The search tool Catfish and the video player gxine have been added.
AntiX is designed to work on computers with as little as 64 MB RAM and Pentium II or equivalent AMD processors, but not K5/K6 processors.
See: http://antix.mepis.com.
Firefox 3 Release Candidate 1 is outAfter almost 3 years of fixes and feature development, Firefox 3 Release Candidate 1 is now available for download.
Many new features and changes to the platform for Firefox 3 can be previewed now, including security enhancements and performance improvements over both FireFox 2 and IE 7. FF 3 will also do a better job at memory management.
Most new features are stable in the RC version, but several users have posted that about half of their Mozilla extensions, which worked well with Beta 4 and 5, are not working with the new RC1. The release notes mention this problem and add the following caution: "Poorly designed or incompatible extensions can cause problems with your browser, including make it crash, slow down page display, etc.". Mozilla recommends starting FF 3 in safe mode and removing the offending extension to resume normal operation.
Firefox 3 Release Candidate 1 is available in more than 45 languages as a public preview and can be downloaded from the Firefox Release Candidates page.
Release notes: http://www.mozilla.com/en-US/firefox/3.0rc1/releasenotes/
Downloads: http://www.mozilla.com/en-US/firefox/all-rc.html
Adobe Flash Player 10 beta released for Linux
Adobe's latest Flash Player, code-named Astro, was released for Linux.
Adobe considers this "an opportunity for developers and consumers to test
and provide early feedback to Adobe on new features, enhancements, and
compatibility with previously authored content".
http://labs.adobe.com/technologies/flashplayer10/
Melas v0.10.0
A new version of Melas, a system to easily build and package software used
to create complete installable packages with dependency checks, was
released on May 21. It has several bug-fixes and some new features,
including the ability to generate Debian/Ubuntu-compatible dependency
strings, integrated fakeroot for installer targets, and several other
additions and fixes.i
http://www.igelle.net/archives/21
Traffic ControlSpamAssassin just got a boost in its spam-catching ability with the
release of Traffic Control by MailChannels. According to Justin Mason,
creator of SpamAssassin, "It is clear that there is no perfect defense to
spam, and while SpamAssassin provides a level of protection, it can be
resource-intensive. Traffic Control for SpamAssassin provides comprehensive
coverage of a wide spectrum of spam and other threats, while delivering
major scalability benefits". The commercial use of Traffic Control requires
a license, but it is completly free for non-commercial use, so if you use
SpamAssassin, be sure to grab your copy.
Downloads: http://mailchannels.com/download
Press: http://news.mailchannels.com/2008_05_01_archive.html#1463842964922058052
Sun Unveils New Quad-Core AMD Opteron SystemsSun Microsystems announced its first Sun Fire and Sun Blade systems powered by Quad-Core AMD Opteron processors, bringing increased performance and scalability. The Sun Fire X4140, Sun Fire X4240, and Sun Fire X4440 servers, the newest systems in Sun's x64 server line, give customers better energy efficiency, computer and memory density and scalability powered by Quad-Core AMD Opteron processors. The new Sun Fire systems offer a choice of operating systems including the OpenSolaris, Linux, Windows, and VMware.
For more information on pricing and features, please visit: http://www.sun.com/amd
To take advantage of special offers and promotions for these servers,
including Sun's Try and Buy program, visit these URLs:
http://www.sun.com/promotions/campaigns/index.jsp?cid=ti_105
http://www.sun.com/tryandbuy
http://www.sun.com/tradeins/offerings/opteron.jsp
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

Triggers are pieces of code executed automatically when a certain action happens. That action can be any kind of data manipulation (insertion, update, or deletion). It can also be executed before or after the actual data manipulation, having different options and uses (validating data, allowing or disallowing data manipulations, changing other data, etc.).
In PostgreSQL, triggers are special stored procedures - so everything we saw on the last article can be used here, too. Let's go down to an example:
This can be used on a web page, or something similar. We will have a table to store the ID and IP of each access (you can store any information you want here, such as referrer, time and date, etc.), and another table with a single row to store the actual page views (this can be extended to have an ID for each page on your site, storing individual hits.) Here is the SQL to create these tables:
CREATE TABLE access ( access_id serial NOT NULL PRIMARY KEY, access_ip text ); CREATE TABLE hit ( hit_id serial NOT NULL PRIMARY KEY, hit_value integer ); insert into hit values(0, 0);
We'll want to increment the "hit_value" of ID 0 every time an access is recorded. We could use a simple "select count()" to count accesses, but that would mean losing the count when you do a clean up on the access table. (We will not want all that data there forever, will we?) To do it right, first we need to create a procedure that increments the "hit" table when "hit_id" = 0. This is the SQL to create this procedure:
create or replace function add_hit() returns TRIGGER as $$ begin if(TG_OP='INSERT') then update hit set hit_value = (select hit_value from hit where hit_id = 0) +1 where hit_id = 0; end if; return new; end; $$ Language PLPGSQL;
Here, we see three new commands/features in addition to what we used in the last article in this series: the first one is "returns TRIGGER as $$". This is a trigger-specific return type to hold the changed data that will be stored/updated/deleted from the database, useful when you need to add or change the data before inserting into the database. The other new command is "if(TG_OP='INSERT')". TG_OP will store the operation being executed in the database - useful when you use the same trigger on more than one event (insert/update/delete). And finally, we have "return new". "New" is an internal variable that stores the data after the changes. (In an insert, new is the data being inserted; on an update, new is the existing data after the update; on a delete, new does not exist.) Along with "new", there is also "old", which stores the data before the changes: on delete, old is the data that will be deleted; on an update, old is the data that will be changed, before the change; on an insert, old does not exist.
Now, we will turn our stored procedure into a trigger and activate it. Here is the SQL to do that:
create TRIGGER tg_add_hit before insert on access for each row execute procedure add_hit();
The syntax is pretty simple - "create TRIGGER <trigger name> <before/after> <event(s)> for each <row/statement> execute procedure <procedure name>([parameters])". trigger name is a unique name to identify the trigger, before/after defines if the procedure will be executed before or after the actual data change, events are the events when the trigger will be executed - 'insert', 'update', 'delete', or a mix of them ("on insert or update"). for each row means that the trigger will be executed for each row of data that gets changed, while the for each statement means it will only be executed once, no matter how many rows a single statement modifies. In the end, there's the procedure name and its parameters, if it takes any.
Now, to test this trigger, we'll run "select * from hit" to check the current count (should be 0). Then, insert an access with "insert into access(access_ip) values('111');". Then, do a "select * from hit" again, and you will notice that the count changed.
A classic use of triggers is stock/inventory control - keeping a record of how many of each product you have in stock, and using triggers to change the number of remaining items when some are sold. We will use the following tables in this example:
create table product(
pro_id serial primary key,
pro_name varchar(50),
pro_quant integer);
create table sale(
sale_id serial primary key,
sale_value date default current_date);
create table sale_product(
sp_id serial primary key,
sale_id integer references sale(sale_id),
pro_id integer references product(pro_id),
sp_quant integer);
insert into product(pro_name, pro_quant) values ('Computer', 10);
insert into product(pro_name, pro_quant) values ('Printer', 15);
insert into product(pro_name, pro_quant) values ('Monitor', 10);
insert into sale(sale_id) values (0);
Pretty simple - although I left some "details" (prices, clients, etc.) out of it so we could focus on the quantities and on our trigger. I've also created some basic test data for the products and sales tables. Now, let's create the stored procedure to remove products when they are sold, and activate the trigger for it. Here's the SQL to do that:
create or replace function upd_stock() returns TRIGGER as $$ begin if((TG_OP='DELETE') OR (TG_OP='UPDATE')) then update product set pro_quant = pro_quant + OLD.sp_quant where pro_id = OLD.pro_id; end if; if((TG_OP='UPDATE') OR (TG_OP='INSERT')) then update product set pro_quant = pro_quant - NEW.sp_quant where pro_id = NEW.pro_id; end if; if(TG_OP='DELETE') then return old; else return new; end if; end; $$ Language PLPGSQL; create TRIGGER tg_upd_stock before insert or update or delete on sale_product for each row execute procedure upd_stock();
OK, this one is a bit more complex, so let's go through it slowly. First, it's a trigger that runs on every event ("on insert or update or delete"). If the user is deleting data, it will only give the amount sold back to the stock. If it's an insert, then it will remove only the products being sold from the stock. Finally, if it's updating (changing), then the trigger will first add the old amount back into the product table, then it will remove the new quantity. This is done to prevent data corruption. Even if your system does not support data deletion, for example, this ensures that your database will remain correct, no matter what happens.
Now, if you do want to practice stored procedures and triggers, there are two additions you need to make to this last example. The first one will add a table to store data when you buy stuff and a trigger to add the products to the stock; the second one will add a total to the sales table, add the price of the product to the products table and the price of the product when it was sold to the sale_product table, and create a trigger to add the price of the sold products to the sale total.
PostgreSQL is a very advanced database system, and some of its features can aid you greatly in developing systems, eliminate the need for a considerable amount of external code, and usually result in a faster solution, reduced bandwidth requirements, etc. The options we saw in this series of articles are very powerful but are usually under-used - so it's good to remember that they exist. Who knows - next time you are developing something, they might be exactly what you need.
I hope you enjoyed these articles. In case of any questions or suggestions, make sure to send a Talkback message by clicking the link below.
Talkback: Discuss this article with The Answer Gang
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
gDesklets provides a bunch of easy-to-use yet eye-pleasing applications for the GNU/Linux desktop. Mini-applications called desklets can be developed and executed for the desktop to meet specific needs. Since gDesklets is known to work on KDE and XFCE, along with GNOME, it can provide an enchanting look to the Linux Desktop.
In the case of Debian Etch or Ubuntu 7.xx, installation of gDesklets is as easy as
apt-get install gdesklets
For Fedora users, add the 'freshrpms' repository to the list of repositories for yum. For that, create a 'freshrpm.repo' file in your /etc/yum.repos.d/ directory. The content of the file should be:
[freshrpms] name=FreshRPMs for Fedora Core $releasever - $basearch baseurl=http://ayo.freshrpms.net/fedora/linux/$releasever/$basearch/freshrpms enabled=1 gpgcheck=1 gpgkey=http://freshrpms.net/RPM-GPG-KEY-freshrpms
Now, issue the command
yum install gdesklet
This will install gDesklets on your machine.
For other distributions, source code for the latest gDesklets can be downloaded from http://www.gdesklets.de/ [1]. Following the steps listed below will install gDesklets onto your machine:
wget http://www.gdesklets.de/files/gDesklets-0.35.4.tar.bz2 tar jxvf gDesklets-0.35.4.tar.bz2 cd gDesklets-0.35.4 ./configure make make install
[ When installing software from source, please make sure to never run the steps tar x ..., ./configure and make as root. Always use a non-privileged user account for these steps. -- René ]
We can invoke the gDesklets program by issuing the command "gdesklet" in the shell, or by selecting gDesklets via Applications -> accessories -> gDesklets. However, remember to start it as an ordinary user - you won't be able to invoke gDesklets as the "root" user. Some desklets to be used with gDesklets can be downloaded from the gDesklets Web site. The downloaded desklets can be installed into your system with the help of the gDesklet manager application; to install them, just drag and drop the downloaded *.tar.gz files on the gDesklets manager icon.
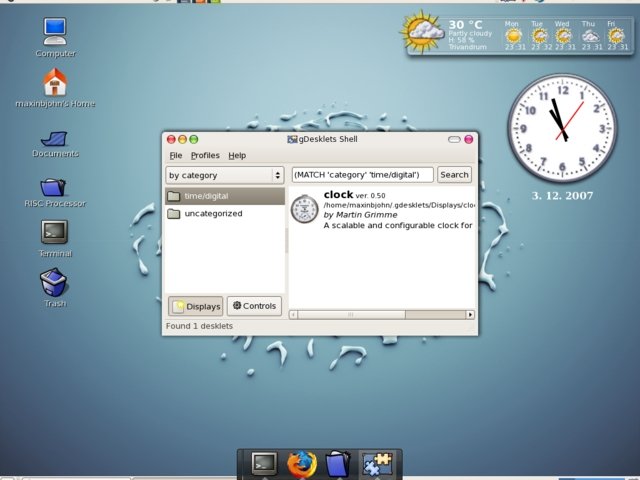
gDesklets is implemented in Python, which is an interpreted, interactive, object-oriented, extensible programming language. The gDesklets' framework looks like this:

The main advantages of Python lie in its clarity and ease of use. Since gDesklets is written in Python, it is both elegant and simple.
Now, let's create our very first desklet. The file structure of an ordinary gDesklet is:
hello.tar.gz: ->hello/ ->hello/helloworld.display ->hello/hello.png
(The content of 'hello.display' is available here.)
The meta tag contains information about your desklet - e.g., the name of the author, name of the desklet, the version, etc. - which can be viewed in the gDesklets manager application. The meta tag is optional for every desklet; the preview file ("hello.png", in this case) is also optional.
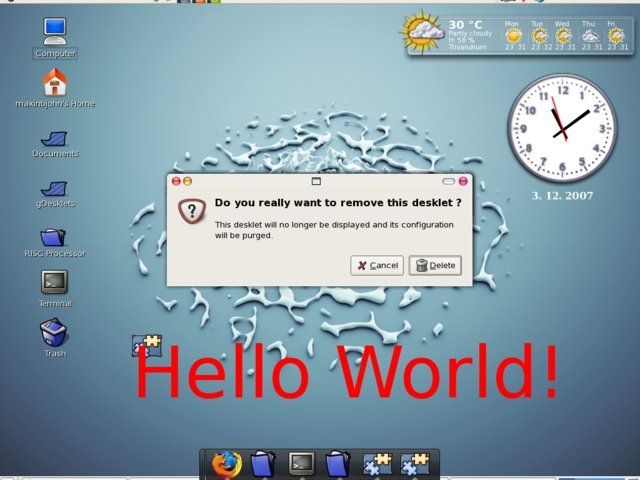
To create our desklet and load it in the gDesklet manager application, perform the following steps:
mkdir hello cp helloworld.display hello cp hello.png hello tar czvf hello.tar.gz hello
Now, the desklet is ready for use and can be loaded into the gDesklets manager. After installation, it can be removed by simply clicking on the desklet and choosing the 'remove' option.
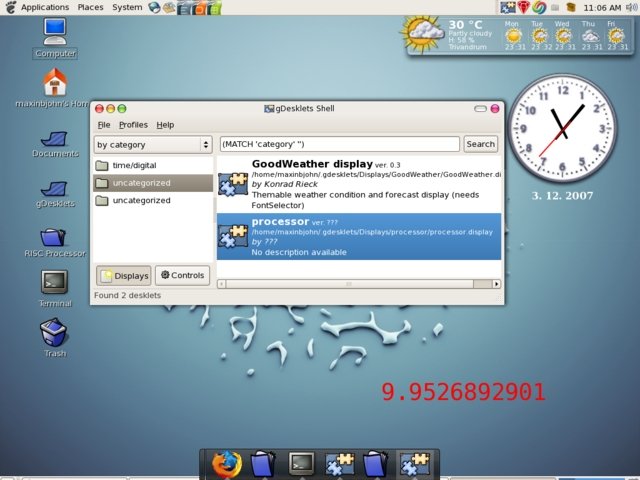
The controls in gDesklets allow your inline scripts access to any kind of data with the help of the 'gdesklets' library. This mechanism maintains the integrity and security of the sandbox scripting environment which is the backbone of the gDesklets. In effect, controls help to share the functionality among desklets without duplicating it. Let's create another simple gDesklet that uses a control to show the second-by-second load average of the processor.
The content of processor.display is available here.
The control tag loads a particular control by the cited interface, and binds it to the cited ID. The first step in using the control in your desklet is to find the control's unique interface identity. For the System interface, which provides information like CPU load, network statistics, memory statistics, etc., the unique interface string is ISystem:4zcicmk4botcub7iypo46t2l7-2. The corresponding unique interface string for each control is obtained from the gDesklets manager application, by browsing through the controls installed in the system.
Then pack the processor desklet, just like we did before:
processor.tar.gz: ->processor/ ->processor/processor.display
Now the processor desklet is ready for deployment via the gDesket manager application. See our desklet in action:
The plotter element in gDesklets allows us to generate graphs of various data such as processor usage, free memory available, network speed, etc. in real time on our desktop. Now, let's dare to plot a real-time graph that shows the number of incoming packets on our eth0 network interface.
(The content of netspeed.display is available here.)
Now, as usual, create the desklet (netspeed.tar.gz) using the netspeed.display file.
netspeed.tar.gz: ->netspeed/ ->netspeed/netspeed.display
The real power of gDesklets lies in the fact that the user can extend its capabilities by writing his or her own controls. Controls are Python classes derived from the Control base class and from the interfaces they implement. Now, let's see how to roll a simple control of our own. Since the control needs to be verified, we will also write a small desklet that uses our "home-made" control.
Most of the controls live in /usr/lib/gdesklets/Controls. We'll create an 'ntp' directory there, and create a control to retrieve the precise time by contacting an NTP server. The Network Time Protocol is a protocol used for synchronizing the clocks of computer systems over packet-switched, variable-latency data networks. Through the gDesklet control and desklet, we will contact the Red Hat NTP server (0.fedora.pool.ntp.org), fetch the time, and display it on the desktop. Please note that this desklet won't be syncing the clocks; it will be just displaying the precise time on the desktop.
The control directory has to include all interface files from which the control inherits. Usually, the filenames of interface files start with an "I" - so here the name of the interface file is Intp.py. The __init__.py is a mandatory file for a control. Every property in the interfaces must be implemented by creating appropriate property objects.
The directory structure of a simple control (here, ntp) looks like this:
ntp/ Intp.py __init__.py
The Intp.py file is:
from libdesklets.controls import Interface, Permission
class Intp(Interface):
ntp_time = Permission.READ
The __init__.py file is:
from libdesklets.controls import Control
from Intp import Intp
from socket import *
import struct
import sys
import time
class ntp(Control, Intp):
def __init__(self):
Control.__init__(self)
pass
def __get_time(self):
Server = ''
EPOCH = 2208988800L
Server = '0.fedora.pool.ntp.org'
client = socket( AF_INET, SOCK_DGRAM )
data = '\x1b' + 47 * '\0'
client.sendto( data, ( Server, 123 ))
data, address = client.recvfrom( 1024 )
if data:
t = struct.unpack( '!12I', data )[10]
t -= EPOCH
return time.ctime(t)
ntp_time= property(__get_time, doc = "the current time")
def get_class():
return ntp
The interface identifiers are made up of a human-readable name given by the interface's author and a random-looking string. That string is based on a checksum of the interface, and is affected by any changes to the interface, except for changes in comments in the desklet code. The gDesklets manager program will auto-generate the interface identifier for each control, so we don't have to worry about the interface identifier for our NTP control.
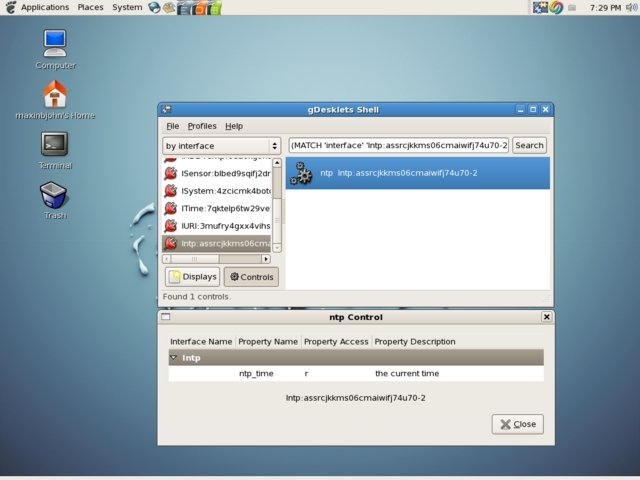
Verification program for our control.
Then, pack the processor desklet, like this:
ntptest.tar.gz: ->ntptest/ ->ntptest/ntptest.display
Now the processor desklet as well as the control is ready for use.
gDesklets is an answer to those who complain that Linux is a geek's operating system; it adds spice to the capabilities of Linux by combining beauty and purpose on the Linux desktop. It also makes life a bit easier for the common GNU/Linux desktop user.
The main source of information about gDesklets is http://www.gdesklets.de/. The Developer's Book is available at http://develbook.gdesklets.de/book.html.
[1] Rick Moen comments: This is called fetching an "upstream tarball", as opposed to a maintained package tailored for the user's Linux distribution, and in my considered view should be a last-resort method of installing any significant software, if one is absolutely certain that no package from or for one's distribution exists. There are several compelling reasons for this preference, and I detailed them a few years ago, when this matter last came up.
Talkback: Discuss this article with The Answer Gang
I am an ardent fan of GNU/Linux from India. I admire the power,
stability and flexibility offered by Linux. I must thank my guru, Mr.
Pramode C. E., for introducing me to the fascinating world of Linux.
I have completed my Masters in Computer Applications from Govt.
Engineering College, Thrissur (Kerala, India) and am presently working at
Ushus Technologies, Thiruvananthapuram, India, as a Software Engineer.
In my spare time, you can find me fiddling with Free Software, free
diving into the depths of Ashtamudi Lake, and practicing Yoga. My other
areas of interest include Python, device drivers, and embedded
systems.

There are tools to monitor the system calls an application makes, but how about monitoring your own written functions - inside the program itself? What if we want to check when a function is entered, which arguments is the function called with, when the function exits, and what the returned value is? This article presents a proof-of-concept tool to achieve this without modifying the application's code.
While the gcc compiler will instrument the code for us, some of the details left to the programmer are both compiler-version dependent and CPU-dependent - namely retrieving the function arguments and return values. Thus, the discussion here is based on experiments with gcc compiler suites 4.1 and 4.2, Intel processors, and binutils 2.18.
We want to address the following points:
The first one is easy: if requested, the compiler will instrument functions and methods, so that when a function/method is entered, a call to an instrumentation function is made, and when the function is exited, a similar instrumentation call is made:
void __cyg_profile_func_enter(void *func, void *callsite);
void __cyg_profile_func_exit(void *func, void *callsite);
This is achieved by compiling the code with the -finstrument-functions flag. The above two functions can be used, for instance, to collect data for coverage or for profiling. We will use them to print a trace of function calls. Furthermore, we can isolate these two functions and the supporting code in an interposition library of our own. This library can be loaded when and if needed, thus leaving the application code basically unchanged.
Now when the function is entered, we get the arguments of the call:
void __cyg_profile_func_enter( void *func, void *callsite )
{
char buf_func[CTRACE_BUF_LEN+1] = {0};
char buf_file[CTRACE_BUF_LEN+1] = {0};
char buf_args[ARG_BUF_LEN + 1] = {0};
pthread_t self = (pthread_t)0;
int *frame = NULL;
int nargs = 0;
self = pthread_self();
frame = (int *)__builtin_frame_address(1); /*of the 'func'*/
/*Which function*/
libtrace_resolve (func, buf_func, CTRACE_BUF_LEN, NULL, 0);
/*From where. KO with optimizations. */
libtrace_resolve (callsite, NULL, 0, buf_file, CTRACE_BUF_LEN);
nargs = nchr(buf_func, ',') + 1; /*Last arg has no comma after*/
nargs += is_cpp(buf_func); /*'this'*/
if (nargs > MAX_ARG_SHOW)
nargs = MAX_ARG_SHOW;
printf("T%p: %p %s %s [from %s]\n",
self, (int*)func, buf_func,
args(buf_args, ARG_BUF_LEN, nargs, frame),
buf_file);
}
And when the function is is exited, we get the return value:
void __cyg_profile_func_exit( void *func, void *callsite )
{
long ret = 0L;
char buf_func[CTRACE_BUF_LEN+1] = {0};
char buf_file[CTRACE_BUF_LEN+1] = {0};
pthread_t self = (pthread_t)0;
GET_EBX(ret);
self = pthread_self();
/*Which function*/
libtrace_resolve (func, buf_func, CTRACE_BUF_LEN, NULL, 0);
printf("T%p: %p %s => %d\n",
self, (int*)func, buf_func,
ret);
SET_EBX(ret);
}
Since these two instrumentation functions are aware of addresses, and we actually want the trace to be readable by humans, we need also a way to resolve symbol addresses to symbol names: this is what libtrace_resolve() does.
First, we have to have the symbol information handy. To achieve this, we compile our application with the '-g' flag. Then, we can map addresses to symbol names. This would normally require writing some code that is aware of the ELF format.
Luckily, there is the binutils package, which comes with a library that does just that - libbfd - and with a tool - addr2line. addr2line is a good example of how to use libbfd, and I have simply used it to wrap around libbfd. The result is the libtrace_resolve() function. For details, please refer to the README in the code accompanying this article.
Since the instrumentation functions are isolated in a stand-alone module, we tell this module the name of the instrumented executable through an environment variable (CTRACE_PROGRAM) that we set before running the program. This is needed to properly init libbfd to search for symbols.
Note: binutils is a work in progress. I have used version 2.18. It does an amazingly good job, although function inlining affects its precision.
To address the first point, the work has been architecture-agnostic. (Actually, libbfd is aware of the architecture, but things are hidden behind its API.) However, to retrieve function arguments and return values, we have to look at the stack, write a bit of architecture-specific code, and exploit some gcc quirks. Again, the compilers I have used were gcc 4.1 and 4.2; later or previous versions might work differently. In short:
\
+------------+ |
| arg 2 | \
+------------+ >- previous function's stack frame
| arg 1 | /
+------------+ |
| ret %eip | /
+============+
| saved %ebp | \
%ebp-> +------------+ |
| | |
| local | \
| variables, | >- current function's stack frame
| etc. | /
| | |
| | |
%esp-> +------------+ /
In an ideal world, the code the compiler generates would make sure that upon instrumenting the exit of a function the return value was set and the CPU registers were pushed on the stack (to ensure the instrumentation function does not affects them). Then, it would call the instrumentation function, and finally pop the registers. This sequence of code would ensure we always get access to the return value in the instrumentation function. The code generated by the compiler is a bit different...
Also, in practice, many of gcc's flags affect the stack layout and registers usage. The most obvious ones are:
In any case, be wary: the flags you use to compile your application may hold hidden surprises.
In my tests with the compilers, all arguments were invariably passed through the stack. Hence, this is trivial business, affected to a small extent by the -fomit-frame-pointer flag - this flag will change the offset at which arguments start.
How many arguments does a function have; how many arguments are on the stack? One way to infer the number of arguments is based on its signature (for C++, beware of the "this" hidden argument), and this is the technique used in __cyg_profile_func_enter().
Once we know the offset where the arguments start on the stack and how many of them there are, we just walk the stack to retrieve their values:
char *args(char *buf, int len, int nargs, int *frame)
{
int i;
int offset;
memset(buf, 0, len);
snprintf(buf, len, "(");
offset = 1;
for (i=0; i<nargs && offset<len; i++) {
offset += snprintf(buf+offset, len-offset, "%d%s",
*(frame+ARG_OFFET+i),
i==nargs-1 ? " ...)" : ", ");
}
return buf;
}
Obtaining the return value proved to be possible only when using the -O0 flag.
Let's look what happens when using this method:
class B {
...
virtual int m1(int i, int j) {printf("B::m1()\n"); f1(i); return 20;}
...
};
is instrumented with -O0:
080496a2 <_ZN1B2m1Eii>:
80496a2: 55 push %ebp
80496a3: 89 e5 mov %esp,%ebp
80496a5: 53 push %ebx
80496a6: 83 ec 24 sub $0x24,%esp
80496a9: 8b 45 04 mov 0x4(%ebp),%eax
80496ac: 89 44 24 04 mov %eax,0x4(%esp)
80496b0: c7 04 24 a2 96 04 08 movl $0x80496a2,(%esp)
80496b7: e8 b0 f4 ff ff call 8048b6c <__cyg_profile_func_enter@plt>
80496bc: c7 04 24 35 9c 04 08 movl $0x8049c35,(%esp)
80496c3: e8 b4 f4 ff ff call 8048b7c <puts@plt>
80496c8: 8b 45 0c mov 0xc(%ebp),%eax
80496cb: 89 04 24 mov %eax,(%esp)
80496ce: e8 9d f8 ff ff call 8048f70 <_Z2f1i>
80496d3: bb 14 00 00 00 mov $0x14,%ebx
80496d8: 8b 45 04 mov 0x4(%ebp),%eax
80496db: 89 44 24 04 mov %eax,0x4(%esp)
80496df: c7 04 24 a2 96 04 08 movl $0x80496a2,(%esp)
80496e6: e8 81 f5 ff ff call 8048c6c <__cyg_profile_func_exit@plt>
80496eb: 89 5d f8 mov %ebx,0xfffffff8(%ebp)
80496ee: eb 27 jmp 8049717 <_ZN1B2m1Eii+0x75>
80496f0: 89 45 f4 mov %eax,0xfffffff4(%ebp)
80496f3: 8b 5d f4 mov 0xfffffff4(%ebp),%ebx
80496f6: 8b 45 04 mov 0x4(%ebp),%eax
80496f9: 89 44 24 04 mov %eax,0x4(%esp)
80496fd: c7 04 24 a2 96 04 08 movl $0x80496a2,(%esp)
8049704: e8 63 f5 ff ff call 8048c6c <__cyg_profile_func_exit@plt>
8049709: 89 5d f4 mov %ebx,0xfffffff4(%ebp)
804970c: 8b 45 f4 mov 0xfffffff4(%ebp),%eax
804970f: 89 04 24 mov %eax,(%esp)
8049712: e8 15 f5 ff ff call 8048c2c <_Unwind_Resume@plt>
8049717: 8b 45 f8 mov 0xfffffff8(%ebp),%eax
804971a: 83 c4 24 add $0x24,%esp
804971d: 5b pop %ebx
804971e: 5d pop %ebp
804971f: c3 ret
Note how the return code is moved into the ebx register - a bit unexpected since, traditionally, the eax register is used for return codes - and then the instrumentation function is called. Good to retrieve the return value, but to avoid the ebx register getting clobbered in the instrumentation function, we'll save it upon entering the function, and restore it when we exit.
When the compilation is done with some degree of optimization (-O1...3; shown here is -O2), the code changes:
080498c0 <_ZN1B2m1Eii>:
80498c0: 55 push %ebp
80498c1: 89 e5 mov %esp,%ebp
80498c3: 53 push %ebx
80498c4: 83 ec 14 sub $0x14,%esp
80498c7: 8b 45 04 mov 0x4(%ebp),%eax
80498ca: c7 04 24 c0 98 04 08 movl $0x80498c0,(%esp)
80498d1: 89 44 24 04 mov %eax,0x4(%esp)
80498d5: e8 12 f4 ff ff call 8048cec <__cyg_profile_func_enter@plt>
80498da: c7 04 24 2d 9c 04 08 movl $0x8049c2d,(%esp)
80498e1: e8 16 f4 ff ff call 8048cfc <puts@plt>
80498e6: 8b 45 0c mov 0xc(%ebp),%eax
80498e9: 89 04 24 mov %eax,(%esp)
80498ec: e8 af f7 ff ff call 80490a0 <_Z2f1i>
80498f1: 8b 45 04 mov 0x4(%ebp),%eax
80498f4: c7 04 24 c0 98 04 08 movl $0x80498c0,(%esp)
80498fb: 89 44 24 04 mov %eax,0x4(%esp)
80498ff: e8 88 f3 ff ff call 8048c8c <__cyg_profile_func_exit@plt>
8049904: 83 c4 14 add $0x14,%esp
8049907: b8 14 00 00 00 mov $0x14,%eax
804990c: 5b pop %ebx
804990d: 5d pop %ebp
804990e: c3 ret
804990f: 89 c3 mov %eax,%ebx
8049911: 8b 45 04 mov 0x4(%ebp),%eax
8049914: c7 04 24 c0 98 04 08 movl $0x80498c0,(%esp)
804991b: 89 44 24 04 mov %eax,0x4(%esp)
804991f: e8 68 f3 ff ff call 8048c8c <__cyg_profile_func_exit@plt>
8049924: 89 1c 24 mov %ebx,(%esp)
8049927: e8 f0 f3 ff ff call 8048d1c <_Unwind_Resume@plt>
804992c: 90 nop
804992d: 90 nop
804992e: 90 nop
804992f: 90 nop
Note how the instrumentation function gets called first, and only then the eax register is set with the return value. Thus, if we absolutely want the return code, we are forced to compile with -O0.
Finally, below are the results. At the shell prompt type:
$ export CTRACE_PROGRAM=./cpptraced $ LD_PRELOAD=./libctrace.so ./cpptraced T0xb7c0f6c0: 0x8048d34 main (0 ...) [from ] ./cpptraced: main(argc=1) T0xb7c0ebb0: 0x80492d8 thread1(void*) (1 ...) [from ] T0xb7c0ebb0: 0x80498b2 D (134605416 ...) [from cpptraced.cpp:91] T0xb7c0ebb0: 0x8049630 B (134605416 ...) [from cpptraced.cpp:66] B::B() T0xb7c0ebb0: 0x8049630 B => -1209622540 [from ] D::D(int=-1210829552) T0xb7c0ebb0: 0x80498b2 D => -1209622540 [from ] Hello World! It's me, thread #1! ./cpptraced: done. T0xb7c0f6c0: 0x8048d34 main => -1212090144 [from ] T0xb740dbb0: 0x8049000 thread2(void*) (2 ...) [from ] T0xb740dbb0: 0x80498b2 D (134605432 ...) [from cpptraced.cpp:137] T0xb740dbb0: 0x8049630 B (134605432 ...) [from cpptraced.cpp:66] B::B() T0xb740dbb0: 0x8049630 B => -1209622540 [from ] D::D(int=-1210829568) T0xb740dbb0: 0x80498b2 D => -1209622540 [from ] Hello World! It's me, thread #2! T#2! T0xb6c0cbb0: 0x8049166 thread3(void*) (3 ...) [from ] T0xb6c0cbb0: 0x80498b2 D (134613288 ...) [from cpptraced.cpp:157] T0xb6c0cbb0: 0x8049630 B (134613288 ...) [from cpptraced.cpp:66] B::B() T0xb6c0cbb0: 0x8049630 B => -1209622540 [from ] D::D(int=0) T0xb6c0cbb0: 0x80498b2 D => -1209622540 [from ] Hello World! It's me, thread #3! T#1! T0xb7c0ebb0: 0x80490dc wrap_strerror_r (134525680 ...) [from cpptraced.cpp:105] T0xb7c0ebb0: 0x80490dc wrap_strerror_r => -1210887643 [from ] T#1+M2 (Success) T0xb740dbb0: 0x80495a0 D::m1(int, int) (134605432, 3, 4 ...) [from cpptraced.cpp:141] D::m1() T0xb740dbb0: 0x8049522 B::m2(int) (134605432, 14 ...) [from cpptraced.cpp:69] B::m2() T0xb740dbb0: 0x8048f70 f1 (14 ...) [from cpptraced.cpp:55] f1 14 T0xb740dbb0: 0x8048ee0 f2(int) (74 ...) [from cpptraced.cpp:44] f2 74 T0xb740dbb0: 0x8048e5e f3 (144 ...) [from cpptraced.cpp:36] f3 144 T0xb740dbb0: 0x8048e5e f3 => 80 [from ] T0xb740dbb0: 0x8048ee0 f2(int) => 70 [from ] T0xb740dbb0: 0x8048f70 f1 => 60 [from ] T0xb740dbb0: 0x8049522 B::m2(int) => 21 [from ] T0xb740dbb0: 0x80495a0 D::m1(int, int) => 30 [from ] T#2! T#3!
Note how libbfd fails to resolve some addresses when the function gets inlined.
[ The example code in this article is available here:
or here as a single tarball containing all of the above.
Make sure you use binutils 2.18 or you miss some important header files (Debian Etch
currently only has binutils 2.17). You can try the code without installing binutils 2.18, the
Makefile already accesses the binutils build directory (just change the path to wherever
you unpacked the sources).
Please note that the code was intended to be used on the IA32 32-bit Intel platform.
We tried to run it on a x86_64 system with some modifications but decided to leave
it that way. If you port the examples to the AMD x86_64 platform,
please send patches to the author.
-- René
]
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/melinte.jpg)
Aurelian is a software programmer by trade. Sometimes he programmed Windows, sometimes Linux and sometimes embedded systems. He discovered Linux in 1998 and enjoys using it ever since. He is currently settled with Debian.
By Joey Prestia

Crontab is a very useful command used to run unattended scheduled tasks, which can decrease administrative time. There are also two similar commands: anacron and at. Anacron is for scheduling commands that do not require the computer to be on at all times; Anacron uses day-, week-, and month-type intervals. The "at" command runs a task once, at a set time, and can also be very useful. But most commonly used is crontab, because it is more versatile, and can be customized to run at any time interval.
At our college, we have several servers running scripts which back up critical data during off peak hours. We have automated these procedures by using cron. For example, the backup script brings several services to a stop, performs an rsync of any changes from the hot server to a duplicate cold server, performs a standard tape archive backup, and finally brings the halted services back online. I sure am glad I don't have to be present at 1:00 AM, when this operation is performed! Thanks to cron, all I have to do is load and unload the backup devices and check my mail every morning to make sure all went well. I also have other programs that are run periodically - I would hate to have to remember to run these scripts every day.
In administering your system, you will also need to use cron quite a bit. This is done via the 'crontab' file, which lists the times and the scripts to be executed. The system also has a default crontab file, /etc/crontab, which runs certain scripts at set times: hourly, daily, weekly, and monthly. This file can be kind of cryptic-looking at first - so let's take the mystery out of it by breaking it down.
[root@localhost ~]# cat /etc/crontab SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root HOME=/ # run-parts 01 * * * * root run-parts /etc/cron.hourly 02 4 * * * root run-parts /etc/cron.daily 22 4 * * 0 root run-parts /etc/cron.weekly 42 4 1 * * root run-parts /etc/cron.monthly [root@localhost ~]#
The first part simply sets a few variables:
The time field seems to be the part that everyone has problems with - unless you're familiar with it, it can seem pretty cryptic. The rest is very straightforward. The user column specifies the 'run-as' user, and the "run-parts" command runs the scripts in the specified directory. Note that the directories are named by the interval at which they're run; you could just place your scripts in the directory you wanted, and they would be run at the times that are already set in the time section. This is not a good idea, though, because you can forget they're in there. It's by far better to edit your crontab file and create your own cron job, because it's easier to get a listing of your cron jobs this way and fine-tune them through via the crontab command. Keep in mind that this is the system crontab file (it runs the system maintenance scripts and programs), so a user's crontab will look a little different - in fact, the structure will be different - so don't try to replicate this.
# Time User Command Path 01 * * * * root run-parts /etc/cron.hourly 02 4 * * * root run-parts /etc/cron.daily 22 4 * * 0 root run-parts /etc/cron.weekly 42 4 1 * * root run-parts /etc/cron.monthly
There are two files that specify which users can and cannot use crontab: /etc/cron.allow and /etc/cron.deny. Usually, only cron.deny exists, and it really couldn't be much simpler: If cron.deny is present, and the user's username is in it (one user per line), then he or she is denied use of the crontab command. If cron.allow is present, then only users listed (one per line) in this file are allowed crontab use.
In the crontab file, there are six fields for each entry, each field separated by spaces or tabs.
Minute - 0-59.
Hour - 0-23 24-hour format.
Day - 1-31 Day of the month.
Month - 1-12 Month of the year.
Weekday - 0-6 Day of the week. 0 refers to Sunday.
In the file, this would look as follows (the comments aren't necessary, but they can be very convenient as a reminder):
# min(0-59) hours(0-23) day(1-31) month(1-12) dow(0-6) command 34 2 * * * sh /root/backup.sh
This example runs, at 2:34 AM every day of the month, every month of the year, every day of the week, the backup script called in the last column by "sh /root/backup.sh".
[ This, of course, requires the script to be written in strict 'sh' syntax - e.g., any "Bash-isms" would cause errors. As is the usual case with shell scripts, using a shebang which specifies the desired shell, making the script executable, and running it simply by specifying the name offers more precise control over the execution environment. -- Ben ]
A star in any position means 'every interval'; that is, a star in the 'minutes' slot would mean "execute this every minute".
Let's set up a cron task, just to see how easy it really is to do. The command we run is crontab -e, which will bring up a vi editor session [1] in which we set up our cron task. Also, you can space the numbers as far apart as you want, but I would recommend getting in the habit of using just one single space because you may need the extra space for the absolute path to whatever command you're running.
[root@localhost ~]# crontab -e
Now enter the following line:
* * * * * /usr/bin/wall "Hello From Crontab"
When you save it, you should see the following output:
crontab: installing new crontab [root@localhost ~]#
In a few moments, you will see a message:
Broadcast message from root (Thu Apr 3 14:52:01 2008): Hello From Crontab
This message will continue every minute, because we put stars in every time field; if we do not remove this crontab after we're satisfied, we will be greeted every minute for the rest of our lives. This is also a good demonstration of what crontab can do if you make a mistake! We will need to execute "crontab -r" to remove the entry.
[root@localhost ~]# crontab -r
Now, say at a certain time in the future you need to start the Apache 'httpd' Web server. We could use a cron job to do this. First, we'll check to see that httpd is not running. Then, we'll do a "date" command to get the current time, so we can set the service to run in the future.
[root@localhost ~]# service httpd status httpd is stopped [root@localhost ~]# [root@localhost ~]# date Thu Apr 3 15:45:32 MST 2008 [root@localhost ~]#
We can now easily figure out what 10 minutes from now will be, execute crontab -e in the editor, and write a simple crontab file, remembering the format.
# min(0-59) hours(0-23) day(1-31) month(1-12) dow(0-6) command 55 15 * * * /sbin/service httpd start
For now, just use stars for the day, month, and day of week, and only one space between elements; some distros complain if you have more spaces. So, enter something like this:
55 15 * * * /sbin/service httpd start
[root@localhost ~]# crontab -e crontab: Installing new crontab
If you made any mistakes, 'crontab' will tell you about it right as you close the editor. Assuming that everything was right, though, we will have the Apache Web server running less than ten minutes from now. You can use "crontab -l" to list your jobs at any time, to see what is in your crontab and when these jobs are set to run:
[root@localhost ~]# crontab -l 55 15 * * * /sbin/service httpd start
Yours should look similar. What this means, though, is that 'httpd' is still set to run every single day at the specified time. Again, we'll remove it by executing "crontab -r" to delete all the entries in the file.
[root@localhost ~]# crontab -r
The combinations seem endless. There are also additional variations for specifying time: "20-27" specifies a range; "3,4,7,8" mean just those intervals for that selection; and */5 would be every 5th interval. Another feature of cron is that, upon completion of a job, it will mail the command output to the user who set up the cron job unless that feature is disabled.
This crontab entry would run the command every 15 and 30 minutes after every hour, during the month of May:
15,30 * * 5 * /usr/bin/command
To run a backup script on just Sundays, Mondays, and Tuesdays at 2:12 AM, the entry would be:
12 2 * * 0-2 sh /root/backup.sh
To run a script at 12 minutes after every 3rd hour of every day, the entry would look like this:
12 */3 * * * sh /root/script.sh
To get cron to write the output of the commands to a log, you can append something like this to the command entry:
12 */3 * * * sh /root/script.sh >> /root/script.log 2>&1
To have cron suppress the e-mail:
12 */3 * * * sh /root/script.sh > /dev/null 2>&1
This is a sample of cron output that would end up in the mail
From root@localhost.localdomain Thu Apr 3 12:08:01 2008 Date: Thu, 3 Apr 2008 12:08:01 -0700 From: root@localhost.localdomain (Cron Daemon) To: root@localhost.localdomain Subject: Cron <root@localhost> sh /root/s.sh Content-Type: text/plain; charset=UTF-8 Auto-Submitted: auto-generated X-Cron-Env: <SHELL=/bin/sh> X-Cron-Env: <HOME=/root> X-Cron-Env: <PATH=/usr/bin:/bin> X-Cron-Env: <LOGNAME=root> X-Cron-Env: <USER=root> test
crontab -e - Edits the current crontab, or creates a new one.
crontab -l - Lists the contents of the crontab file.
crontab -r - Removes the crontab file.
crontab -u - Edits user's crontab.
[1] Rick Moen comments: Strictly speaking, on most systems, "crontab -e" will invoke whatever is defined by the VISUAL or EDITOR environment variables.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/prestia.jpg)
Joey was born in Phoenix and started programming at the age fourteen on a Timex Sinclair 1000. He was driven by hopes he might be able to do something with this early model computer. He soon became proficient in the BASIC and Assembly programming languages. Joey became a programmer in 1990 and added COBOL, Fortran, and Pascal to his repertoire of programming languages. Since then has become obsessed with just about every aspect of computer science. He became enlightened and discovered RedHat Linux in 2002 when someone gave him RedHat version six. This started off a new passion centered around Linux. Currently Joey is completing his degree in Linux Networking and working on campus for the college's RedHat Academy in Arizona. He is also on the staff of the Linux Gazette as the Mirror Coordinator.
I have a database that I'm working on, and sometimes I need to work on it on my laptop. However, the database is really demanding, and it is just too slow on my laptop's hard disk. I quickly found out that the limitation was the speed of the hard drive, and not so much the CPU. What I needed was a fast external hard drive. Anyway, I always wanted to play with a RAID system.
There are three parameters of drive speed:
I do not need fast read/write speed, as the amount of information that I retrieve from the database is tiny and the db is almost entirely read-only. However, I do need fast access time: the database is huge, and I need to retrieve information from different positions in the database very quickly. That is, I need very low access times, acceptable reading speed, and I do not care about writing.
It is well known that the so-called "solid-state disks" (SSD) have very low access times. I could have tried to buy an SSD, but being a tinkerer, I decided for another option. Thumb drives / flash drives / pen drives are also a kind of SSDs, one could say - but they have lousy transfer rates. In the end, I decided to create a software RAID using four 2GB USB drives. I bought
Prerequisites: you need the mdadm tool (in Debian, simply run apt-get install mdadm).
Insert the drives into the hub, and attach the hub to the computer. Note: if GNOME or whatever mounts the disks automatically, unmount them before continuing. First, it is necessary to find out the names of the devices that were attached:
dmesg | grep "Attached SCSI" sd 56:0:0:0: [sde] Attached SCSI removable disk sd 57:0:0:0: [sdf] Attached SCSI removable disk sd 58:0:0:0: [sdg] Attached SCSI removable disk sd 59:0:0:0: [sdh] Attached SCSI removable disk
OK, the devices are /dev/sde, /dev/sdf, /dev/sdg/, /dev/sdh. I want a RAID-0; that is, no redundancy, and 4x2GB=8GB of space. Creating the RAID is simple:
mdadm --create --verbose /dev/md0 --level=0 --raid-devices=4 /dev/sd{e,f,g,h}
This way, we have a new block device that can be formatted. I use ext2, since reliability / journaling plays no role:
mkfs.ext2 /dev/md0 tune2fs -c 0 -j 0 /dev/md0 mount /dev/md0 /mnt
The first command creates the filesystem ("formats" the device); the second disables regular checks. Finally, the third command mounts the RAID on the filesystem so we can write data to it and read from it.
Before you stop the array, run the following (and save the output somewhere):
mdadm --detail /dev/md0
To stop the array that is running, first unmount the directory (umount /mnt) and then stop the array:
mdadm --stop /dev/md0
Now, you can safely remove the disks and, for example, plug them into another machine.
Before you can use your RAID again, you need to "assemble" it. This is easy if you have not removed the disk and try the assembly on the same machine. In that case, you can just type:
mdadm --verbose -A /dev/md0 /dev/sd{e,f,g,h}
However, what if the device letters have changed (e.g. not e-h, but i,j.k,l)? Well, you could find out again what the letters are. But there is a better solution. Remember I told you to save the output from "mdadm --detail"? It contained a line like that:
UUID : d7ea744f:c3963d02:982f0012:7010779c
Based on this UUID, we can easily "assemble the array" on just any computer :
mdadm --verbose -A /dev/md0 -u d7ea744f:c3963d02:982f0012:7010779c
You can also enter this information in the config file /etc/mdadm/mdadm.conf
| Test | Description | Results | Comment |
|---|---|---|---|
| hdparm | reading | 52 MB/s | This is twice as good as my laptop, and worse than the 70MB/s of my SATA disk in my workstation |
| dd | writing | 28 MB/s | Half of what my workstation disk can do |
| seeker | random access | 0.8-1ms | This is 10-20 times better than an ordinary hard disk |
apt-get install hdparm). The command line is as follows:
hdparm -t /dev/md0
dd if=/dev/zero of=/tmp/test2.bin bs=1M count=1024 conv=fsync
seeker /dev/md0
I have explained here how to create a RAID-0 from four USB thumb drives. However, most of what I was explaining here applies also to other RAID types and other disk drives. Even more so! You can combine just about any devices into a RAID. Well, it only makes sense if the devices have similar sizes, but (i) you can create a RAID out of RAIDs (e.g., join two 2GB USB sticks into a RAID0 /dev/md0, then join /dev/md0 with a 4GB USB stick to get a RAID0 of the size of 8GB...) and (ii) you can combine devices of different sizes using LVM (the logical volume manager).
Apart from some mistakes I made because I did not know 'mdadm', there were no problems. If you run into any, generally two things are of an immense help:
tail -f /var/log/messages
Keywords: usb flash stick thumb drive pendrive linux raid raid0 mdadm
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/weiner.jpg)
January Weiner is a biologist who uses computational tools to investigate evolutionary processes. He is a postdoc in a bioinformatics group.
More XKCD cartoons can be found here. '; digg_topic = 'linux_unix';
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
These images are scaled down to minimize horizontal scrolling.
Flash problems?All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Mulyadi Santosa [mulyadi.santosa at gmail.com]
Hi...
On Jan 28, 2008 9:08 AM, Ben Okopnik <ben@linuxgazette.net> wrote:
> You have nothing to be sorry about, and no reason to feel stupid; > everything worked exactly as it was supposed to. "Stupid" would be > beating up on yourself when you've done everything right and achieved a > good result.
And this is why I put more respect to you. Anyway, I share that tips
at the same time I celebrate my birthday
regards,
Mulyadi.
[ Thread continues here (18 messages/19.63kB) ]
Kat Tanaka Okopnik [kat at linuxgazette.net]
Pardon the hedge latin. Thought TAGistas might be interested in this news item:
http://www.techdirt.com/articles/20080104/023101.shtml
Spammer Alan Ralsky Finally Indicted
[...] The charges include: "conspiracy, fraud in connection with electronic mail, computer fraud, mail fraud and wire fraud." That's because Ralsky wasn't just spamming products for sale, he was using a botnet to run a pump-and-dump scam on Chinese penny stocks. It's unclear why it took over two years for the indictment to finally show up, but there are likely to be quite a few folks in the anti-spam community who are thrilled that something finally happened to Ralsky.
-- Kat Tanaka Okopnik Linux Gazette Mailbag Editor kat@linuxgazette.net
[ Thread continues here (2 messages/2.50kB) ]
Martin J Hooper [martinjh at blueyonder.co.uk]
Hey congrats on the 150th issue!!
[ Thread continues here (14 messages/31.31kB) ]
Ben Okopnik [ben at linuxgazette.net]
A very cute site I spotted while surfing PerlMonks.org:
Geek humor at its finest - savvy and subtle.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (11 messages/12.28kB) ]

![[cartoon]](misc/xkcd/security_holes.png "True story: I had to try several times to upload this comic because my ssh key was blacklisted.")