Technology -> DNA Computers
DNA ComputersTo understand DNA computing lets first examine how the conventional computer process information. A conventional computer performs mathematical operations by using electrical impulses to manipulate zeroes and ones on silicon chips. A DNA computer is based on the fact the information is “encoded” within deoxyribonucleic acid (DNA) as as patterns of molecules known as nucleotides. By manipulating the how the nucleotides combine with each other the DNA computer can be made to process data. The branch of computers dealing with DNA computers is called DNA Computing.
The concept of DNA computing was born in 1993, when Professor Leonard Adleman, a mathematician specializing in computer science and cryptography accidentally stumbled upon the similarities between conventional computers and DNA while reading a book by James Watson. A little more than a year after this, in 1994 he developed the first DNA computer. This computer solved the traveling salesman problem also known as the “Hamiltonian path" problem. In this problem one asks whether there is a path through N partially interconnected "cities" such that a single stop is made in each city without passing through a city twice.
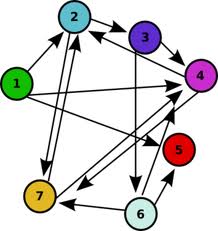
The Hamiltonian Path problem.
The goal is to find a path from the start city to the end city going through every city only once.
To build a DNA computer, techniques developed by biologists to manipulate DNA are used to manufacture a set of DNA strands that represent all of the data points that could possibly be included in an answer to a specific problem. The DNA strands are then turned loose, and they link in every conceivable combination of those data points. Next, researchers filter the results, eliminating all of the incorrect combinations until they are left with the proper answer.
Using this meathod the First DNA computer solved the “Traveling salesman” problem. Prof. Adleman created strands in a way that they would bind only when the destination of one connection matched the source of another. The actual DNA was then fabricated and mixed together so that all possible bindings would occur. He then extracted all the molecules that had the correct length and which contained the code segments for all the cities effectively extracting the final solution.
We can see that DNA computers use radically different components but inspite of this the basic method of computation is the same in both the systems. The difference between the two lies in the speed in which the computations are performed. The common desktop computer can perform 10^8 operations per second (ops) and a super computer can achieve 10^12 ops. In sharp contrast the DNA computers can achieve speeds up to 10^17 ops. The massive parallel computing ability of the DNA computer is responsible for this vast difference in speed. In a DNA computer 10^12 DNA strands take part simultaneously in solving a problem.
DNA systems have a lot of advantages over the conventional systems. The most obvious one is the speed of computation. Another advantage DNA systems enjoy is their higher storage capacity than normal systems. DNA code can be any of the 4 DNA bases (A, G, T, and C) while binary code can only be 0 or 1. Thus while a binary code of 4 characters can represent 6 discrete things, a DNA code can represent 64 discrete things. This gives the DNA computer huge storage capacity. It has been computed that 1g of DNA can store approximately the same amount of data as 1 trillion Compact Disks.
Another advantage is that size is not a limiting factor. DNA computer can be shrunk to a size of only a few molecules across. Conventional computers don't enjoy this luxury, they have a limit below which the cost is extremely high and decrease in size is very small so shrinking below that limit is not very practical.
The resources employed by DNA computers are very inexpensive and require virtually no power. The computer use cheap, clean, readily available materials. One estimate indicates that a DNA computer with trillions of parallel processors could be constructed for $100,000.
If we compare the development of the DNA computers to their silicon counterparts they are not even at the valve stage. Currently most of the work on DNA computing is mostly theoretical with the main thrust being on identifying the most promising architectural features needed to perform computations with DNA.
DNA computers can solve almost any problem that the conventional computers can although not all them are solved with higher efficiency. So far no one has found a problem which is perfect for the DNA computer i.e. so far no “killer application” has been found. In words of David Harlan Wood, a university of Delaware professor “DNA computing is a solution looking for a problem”
One of the main problems with DNA computers is that the they take a long time to setup and run. Setting up a simple experiment to solve the traveling salesman problem can take days even weeks. Another problem major is that DNA systems are very error prone and are messy. Although the computations are very fast, it takes some time to extract the final answer from the DNA pool formed during computations and the DNA strands break up with time. So the chances of error increase.
DNA computers have tremendous biomedical usage. In the future it may be possible to have a small DNA computer inside everyone that monitors the health of the tissues around it and if it finds any anomaly direct the production of a corrective drug and trigger its release.
Due to the high capacity and tremendous computing capacity these systems may also have a scope in the artificial intelligence industry. Efforts are on to try to develop an intelligent system using DNA; these systems will have an added advantage of being able to reproduce using the same technique of reproduction as bacteria. Another application is in the nano-robotics field in which robots of the size of a few microns are being developed.
Below are links to external sites containing more information about DNA Computers. If you know some site which should be included here, please let me know.
| Title | Description |
| DNA Computing | DNA computing |
| How DNA Comptuers Work | How DNA Computers would work from HowStuffWorks.com |
| Ferman's Famous Talk | Link to Ferman's famous talk on DNA and Nano computing |
| Meeting on DNA | 5th Annual Meeting on DNA Based computers at MIT |
Home | About Me | About India |Hotlinks | Linux Related |
Mirror | Misc Section | My Blog | Photogallery | Scripts | Tech Section | Contact Me